Reminder of the floating point encoding
Encoding
- = sign bit, = exponent bits, = fraction or mantissa bits
- Value = (in most cases, special values apply e.g. zero and infinity)
- exponent bias = (maximum positive value) e.g. 127 with 8 exponent bits
MX formats
- Due to the limited range of narrow floating-point formats, microscaling (MX) formats were introduced to balance dynamic range and precision.
- These formats are characterized by a block-wise representation where a group of data elements shares a single, common scale factor.
- MX formats include 8-bit (MXFP8), 6-bit (MXFP6), and 4-bit (MXFP4) floating-point types.
- In MXFP4, each element is represented as E2M1, meaning it has 1 sign bit, 2 exponent bits, and 1 mantissa bit.
- This allows MXFP4 to encode the values ±0, ±0.5, ±1, ±1.5, ±2, ±3, ±4, and ±6
MXFP4
-
TLDR; group size = 32, 8 bit scales in (UE8M0)
-
Since original higher-precision values (e.g., FP32 or BF16) often exceed the FP4 range, they must be scaled into the representable range during quantization.
-
Scale factors are typically chosen so that the absolute maximum value (amax) within a block maps to the FP4 maximum representable,
-
. After scaling, high precision values in a tensor are rounded to the nearest FP4-representable number and later decoded back to their original range using the reciprocal of the same scale.
-
To improve hardware efficiency, MX formats store block scale factors in 8 bits.
-
Each block of 32 contiguous elements in a tensor shares a single 8-bit scale factor, stored in an unsigned E8M0 format (UE8M0), which encodes a power-of-two value ranging from to .
NVFP4
- TLDR; group size = 16. Hierarchical scaling ⇒ 8 bit scales in E4M3 at the group level, FP32 scales at the tensor level.
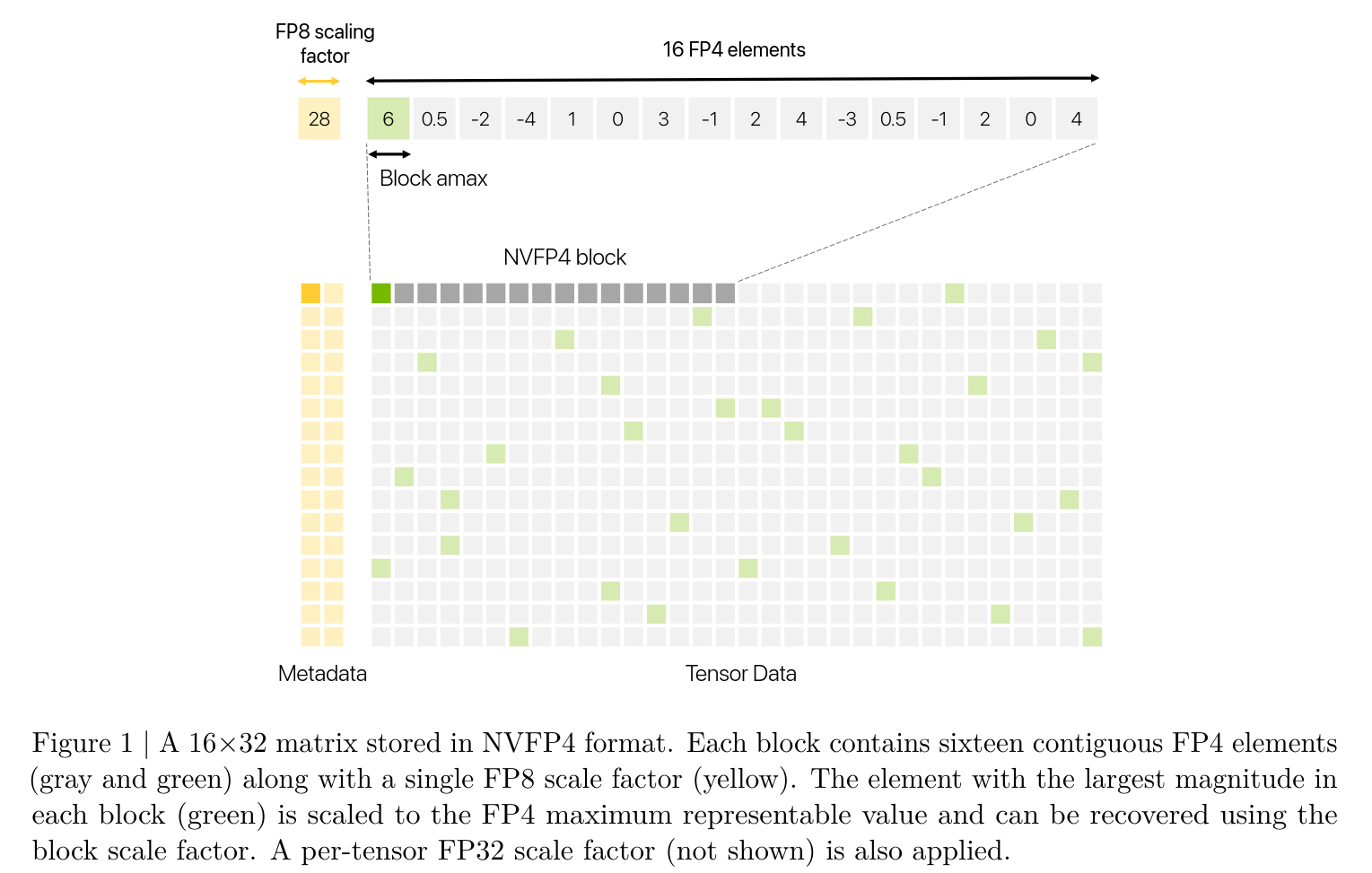
-
NVFP4 is an enhanced 4-bit format that provides improved numerical properties over MXFP4.
-
First, by reducing the block size from 32 to 16 elements, NVFP4 narrows the dynamic range within each block, better fitting values into the FP4 range.
-
Second, block scale factors are stored in E4M3 rather than UE8M0, trading some exponent range for additional mantissa bits.
-
Third, an FP32 scale is applied at the tensor level to retain the range of block scales.
-
With such a two-level microscaling approach, NVFP4 encodes at least 6.25% of values in a block (the amax values in each block of 16 elements) at near-FP8 precision, while storing the remaining values in FP4.
-
In contrast, MXFP4 stores all values in FP4, and can potentially lose up to one binade of dynamic range (and four samples: ±4 and ±6) because of power-of-two scale factor rounding (see Appendix B.4 for details)
Implementation
You choose the FP32 scale so that all per-block “ideal” scales (the ones you’d need to fit values into FP4) fit cleanly into the numeric range of E4M3 and keep good precision. In practice:
- Let for each 16-elem block .
- FP4(E2M1) tops out at about 6 in magnitude, and E4M3 covers roughly .
- Because we have the double layering of scales, the effective range that the “quantized values” can take is
-
Pick a global FP32 scale . (to cover the range we expect out of the first layer of quantization)
-
Then each FP8 block scale is
- first we scale the tensor amax within the range using the fp32 scale
- then we scale the blockwise scale itself within FP8
-
Quantize each value as .
- This can be seen as (1) dequantize the blockscale itself (2) use the dequantized scale to quantize the block
- Dequant is .
- First dequant the block scale, then dequant the block