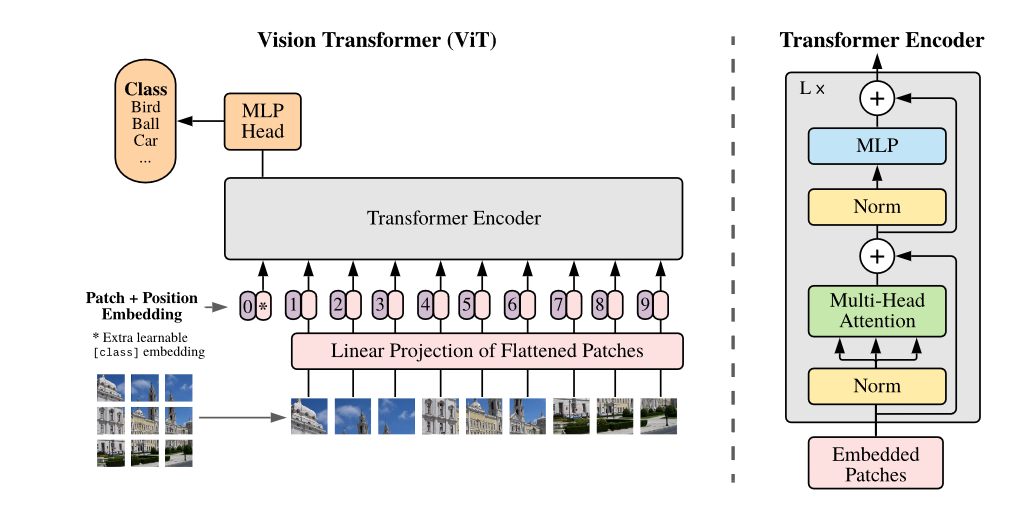
- They split an image into fixed-size patches,
- linearly embed each of them,
- add position embeddings,
- feed the resulting sequence of vectors to a standard Transformer encoder.
- In order to perform classification, they use the standard approach of adding an extra learnable “classification token” to the sequence.
- Diagram
Patchify + getting token sequence
- To do the patchify + linear projection, you can define
patch_embedding = nn.Conv2d(in_channels=config.num_channels,out_channels=self.embed_dim,kernel_size=self.patch_size, stride=self.patch_size, bias=False,) - Then
patch_embeds= patch_embedding(pixel_values).flatten(2)
- This way, you get a token sequence dependent on resolution.
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
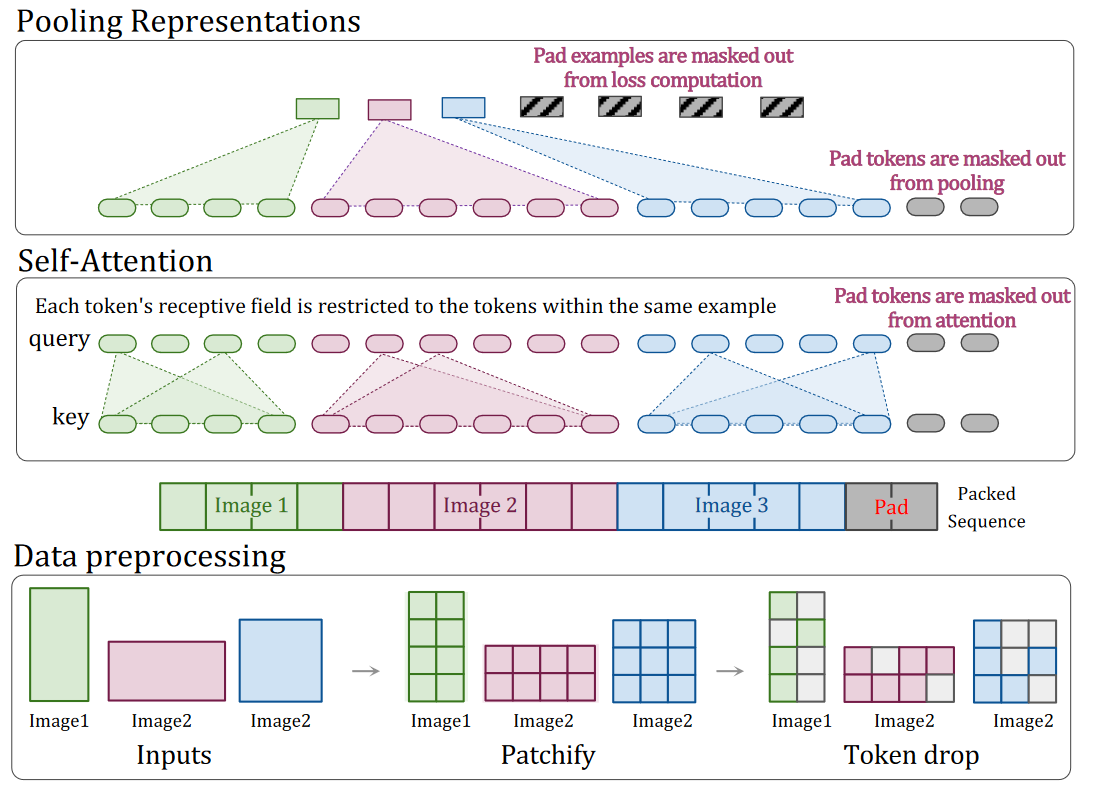
- Inspired by example packing in NLP, where multiple examples are packed into a single sequence to accommodate efficient training on variable length inputs
- Multiple patches from different images are packed in a single sequence— termed Patch n’ Pack —which enables variable resolution while preserving the aspect ratio
- Diagram
Positional embeddings
-
To handle arbitrary resolutions and aspect ratios, we need to revisit the position embeddings.
-
Vanilla ViT Given square images of resolution R×R, a vanilla ViT with patch size P learns 1-D positional embeddings of length . Linearly interpolating these embeddings is necessary to train or evaluate at higher resolution R.
-
Pix2struct introduces learned 2D absolute positional embeddings, whereby positional embeddings of size are learned, and indexed with (x, y) coordinates of each patch. This enables variable aspect ratios, with resolutions of up to . However, every combination of (x, y) coordinates must be seen during training
-
Factorized & fractional positional embeddings. (NaViT)
- To support variable aspect ratios and readily extrapolate to unseen resolutions, they introduce factorized positional embeddings, where we decompose into separate embeddings and of x and y coordinates.
- These are then summed together (alternative combination strategies explored in Section 3.4)
- They consider two schemas:
- absolute embeddings, where is a function of the absolute patch index
- fractional embeddings, where is a function of r = p/side-length, that is, the relative distance along the image
- This provides positional embedding parameters independent of the image size, but partially obfuscates the original aspect ratio, which is then only implicit in the number of patches
- For such functions, they consider simple learned embeddings , sinusoidal embeddings, and the learned Fourier positional embedding used by NeRF
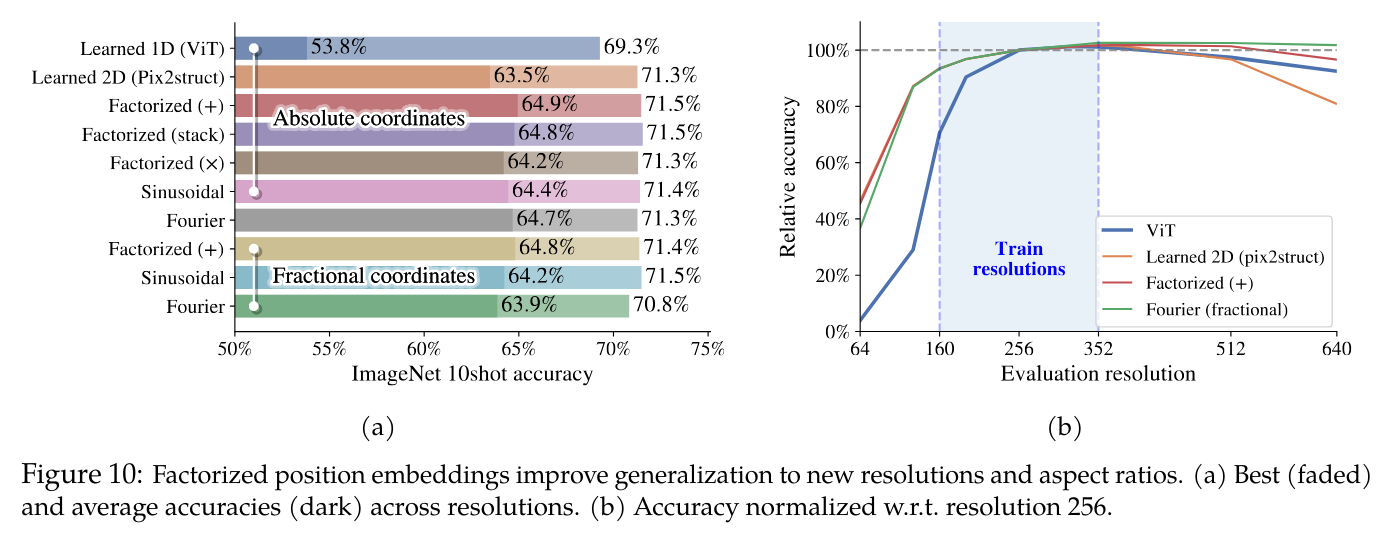
- Factorized position embeddings improve generalization to new resolutions and aspect ratios