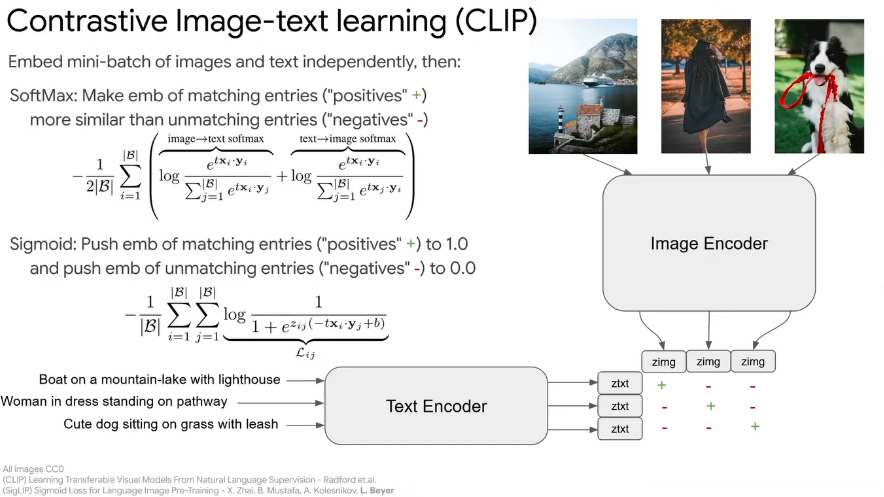
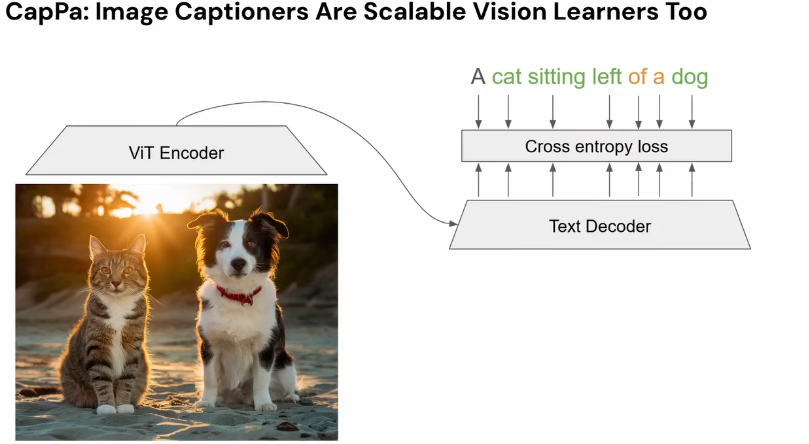
The model can be lazy when using a contrastive loss
Example:
If there are no other cats in the minibatch, the model only needs to know the word cat to successfully make the loss be low, without needing to map the other words in the caption
Similarly, to learn more complex concepts like “left of”, it would require that there is a “right of” example in the minibatch, to force the model to learn
⇒ There’s not enough supervision
Captioning loss is a stronger supervision signal, and successfully fixes those failure modes, this is the current SOTA for training vision encoders