Abstract
- Support fast one-step generation by design, while still allowing multistep sampling to trade compute for sample quality
- trained either by distilling pre-trained diffusion models, or as standalone generative models altogether
- They build on top of the probability flow (PF) ordinary differential equation (ODE) in continuous-time diffusion models, whose trajectories smoothly transition the data distribution into a tractable noise distribution. We propose to learn a model that maps any point at any time step to the trajectory’s starting point.
- self-consistency property: Points on the same trajectory map to the same initial point
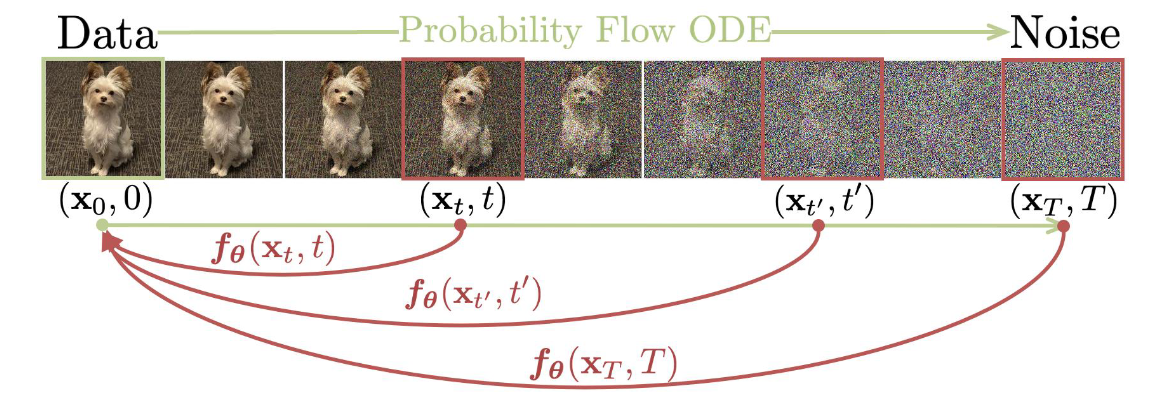
Main idea
- A trained diffusion model, one way or another, estimates the score function of the probability distribution
- whether that’s done directly through score matching
- or through denoising objective, where in practice,
- where is the source noise i.e.
- As soon as you have the score function, assuming it’s a Gaussian Diffusion model, you can sample trajectories from pure noise to new “clean” samples , using an ODE solver (e.g. Euler).
- Then you can enforce the objective that any samples on a trajectory should be mapped back to .
Shortcut models
-
Building on top of the Flow matching training objective, one can define a shortcut model
-
Shortcut models condition the neural network not only on the signal level but also on the requested step size .
-
This allows them to choose the step size at inference time and generate data points using only a few sampling steps and forward passes of the neural network.
-
For the finest step size , shortcut models are trained using the flow matching loss. For larger step sizes , shortcut models are trained using a bootstrap loss that distills two smaller steps (defined as the average of the two midpoints), where stops the gradient:
- The step size is sampled uniformly as a power of two, based on the maximum number of sampling steps , which defines the finest step size .
- The signal level is sampled uniformly over the grid that is reached by the current step size:
- At inference time, one can condition the model on a step size to target sampling steps, without suffering from discretization error because the model has learned to predict the end point of each step.
- In practice, shortcut models generate high-quality samples with 2 or 4 sampling steps, compared to 64 or more steps for typical diffusion models.