TL;DR
- Diffusion Forcing combines the strength of full-sequence diffusion models (like SORA) and next-token models (like LLMs), acting as either or a mix at sampling time via noise as masking, a technique that uses different diffusion noise levels for different tokens.
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
-
New training paradigm where a diffusion model is trained to denoise a set of tokens with independent per-token noise levels
-
They apply Diffusion Forcing to sequence generative modeling by training a causal next-token prediction model to generate one or several future tokens without fully diffusing past ones.
-
Diffusion forcing = teacher forcing + diffusion models
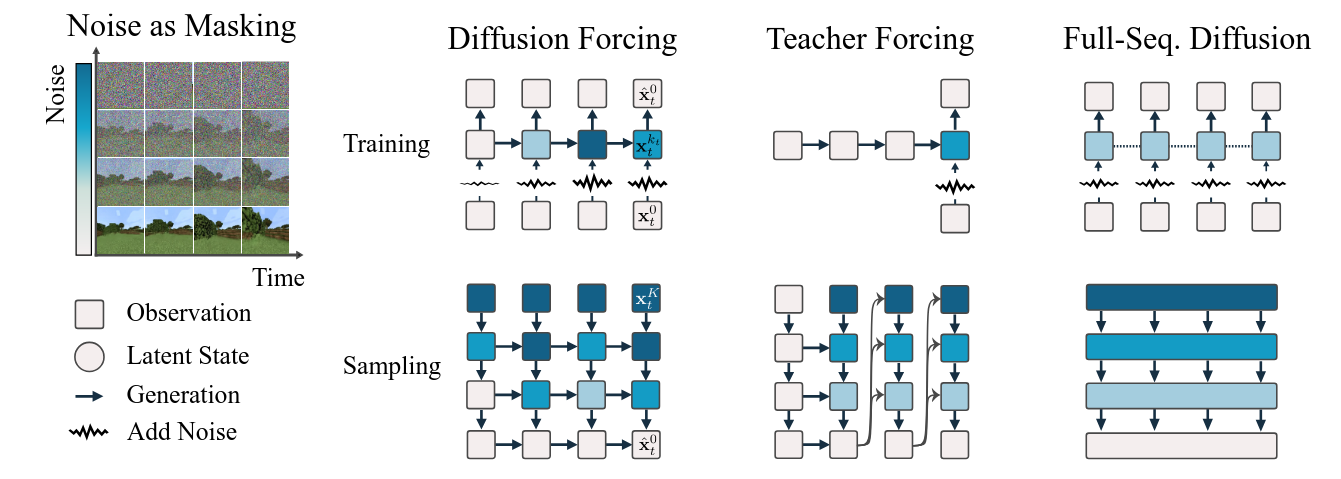
Teacher forcing
- Teacher forcing is such as another name for next-token prediction
- the model predicts the immediate next token based on a ground truth history of previous token
- This results in two limitations:
- (1) there is no mechanism by which one can guide the sampling of a sequence to minimize a certain objective
- (2) current next-token models easily become unstable on continuous data. For example, when attempting to auto-regressively generate a video (as opposed to text [6 ] or vector-quantized latents [34]) past the training horizon, slight errors in frame-to-frame predictions accumulate and the model diverges.
Full-sequence diffusion
- Commonly used in video generation and long-horizon planning, one directly models the joint distribution of a fixed number of tokens by diffusing their concatenation, where the noise level is identical across all tokens.
- This allows to guide sampling to a desirable sequence, invaluable in decision-making (planning) applications.
- They further excel at generating continuous signals such as video
Diffusion forcing
-
You get
- variable-length generation (next-token models)
- ability to guide sampling to desirable trajectories (full-sequence diffusion)
- rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge
-
Training and sampling paradigm where each token is associated with a random, independent noise level, and where tokens can be denoised according to arbitrary, independent, per-token schedules through a shared next-or-next-few-token prediction model.
-
For causal data, they enforce that future tokens depend on past ones.
-
The independent noise per token unlocks variable length generation, as past fully decoded tokens can just be considered to have zero noise