Summary
-
We want continuous embeddings for understanding
-
We want discrete image tokens for auto-regressive generation
-
If we use both, this generally forces the model to process different image tokens types, one from high-level semantic space, and one from low-level spatial space
- This creates significant task conflict, can create competition, and limit capacity
Manzano
Architecture
-
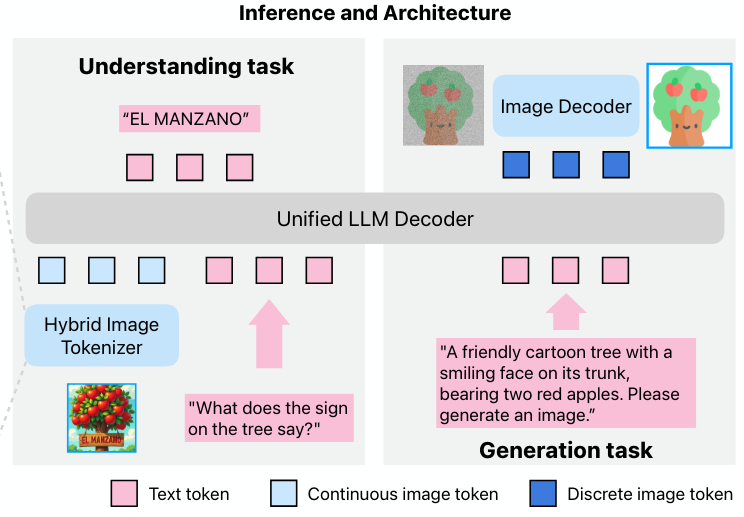
Manzano employs a unified shared visual encoder with two lightweight and specialized adapters:
- a continuous adapter for understanding tasks
- a discrete adapter for generation
-
Because two adaptors originate from the same encoder, it yields hybrid representations from a homogeneous source, significantly mitigating task conflict in the LLM.
-
To obtain the two adapters, they first pre-train the hybrid tokenizer with a small LLM decoder to pre-align the image features with some LLM feature space.
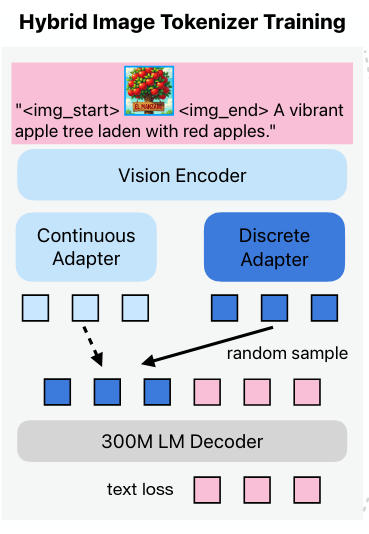
- During training, one of the adapter output is randomly chosen and passed to a small LLM decoder for alignment.
-
They leverage a diffusion image decoder to render pixels by taking the generated image tokens as conditioning. (it’s trained from scratch)
Training
-
The autoregressive multimodal LLMs are jointly trained on a mixture of pure text, image understanding, and image generation data.
-
Joint recipe to learn image understanding and generation simultaneously.
-
This training consists of three stages:
- a pre-training stage on a large-scale corpus of text-only,
- interleaved image-text
- image-to-text (IT),
- and text-to-image (TI) data;
- a continued pre-training stage on higher-quality IT and TI data
- a supervised fine-tuning (SFT) stage on curated text, IT, and TI instruction data
- a pre-training stage on a large-scale corpus of text-only,
-
They freeze the vision encoder and discrete adapter during training to ensure that the codebook size stays fixed.