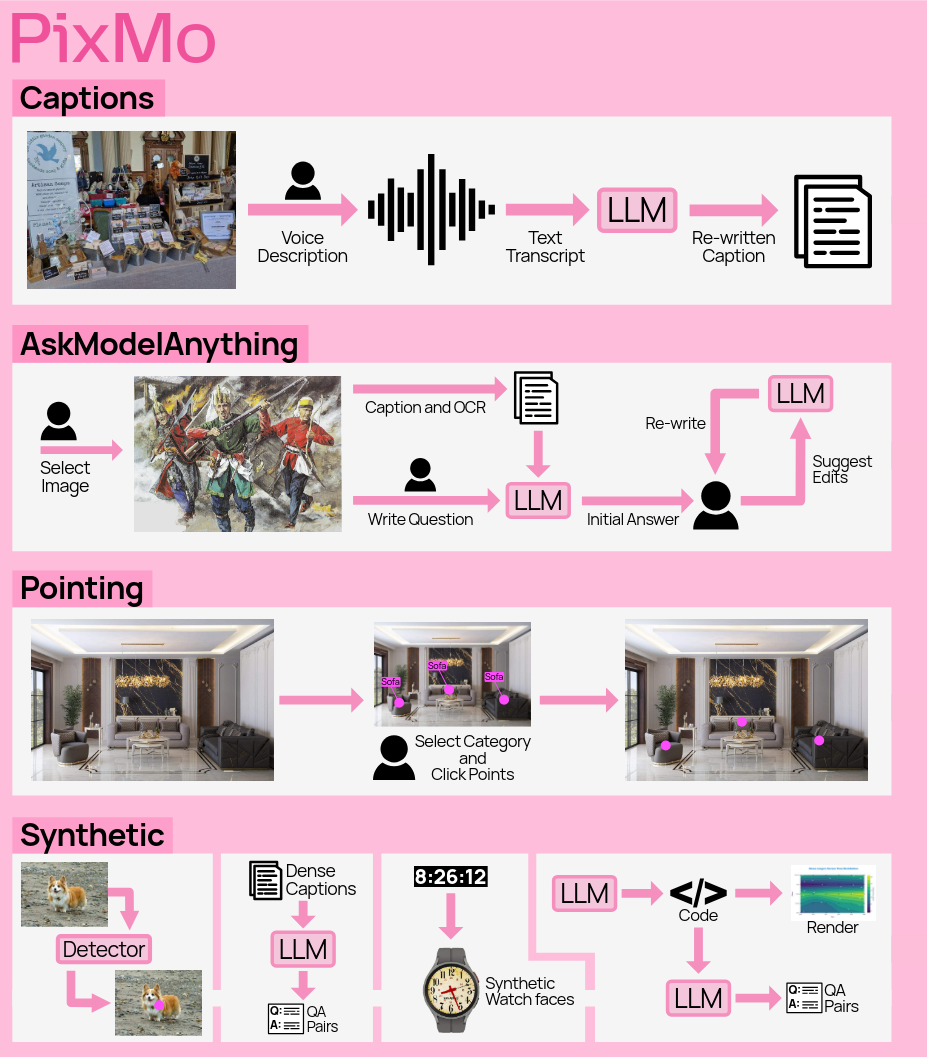
PixMo (data)
Summary
-
**
-
Interesting details
- Using points enables us to collect grounding data much faster than would be possible using bounding boxes or segmentation masks since it is much easier to annotate
- ~2.3 million grounding annotations
- also improves counting accuracy by forcing the model to point first
- Using points enables us to collect grounding data much faster than would be possible using bounding boxes or segmentation masks since it is much easier to annotate
-
PixMo-Cap
- sourcing web images across ∼70 diverse topics (e.g., street signs, memes, food, drawings, websites, blurry photos, etc.).
- For each image, three annotators initially provided detailed descriptions by speaking for at least 60 seconds.
- prompted the annotators with the following questions to answer in their spoken image descriptions.
- What is the image at first glance?
- What are the objects and their counts?
- What does the text say?
- What are the positions of the objects?
- What subtle details are noticeable?
- What is in the background?
- What is the style and color?
-
PixMo-Points.
- They collected pointing data to achieve three goals: (1) enable the model to point to items described by text, (2) enable the model to count by pointing, and (3) use pointing as a form of visual explanation when answering questions.
- Pointing can be referred to as visual grounding
- For the first two goals, annotators were asked to point at something in an image, describe it, and then point to each instance of it in the image, ensuring exhaustive coverage
- They also collected “not present” data so models can learn to handle cases where an item is not in the image.
- Pointing data also naturally supports answering counting questions with a chain-of-thought formed by the sequence of points.
- For pointing, we will expect that the model outputs points as plain-text coordinates normalized between 0 and 100. When pointing to multiple items, points are ordered top-down, left-to-right, with each point numbered
- Drawback: pointing capabilities do not generalize well with different numbers of test crops. A small amount of high-res post-training can resolve this issue..
-
PixMo-AskModelAnything
- annotator creates question w.r.t to image
- extract OCR data & caption the image with a captioning model
- feed question & the extracted data to an LLM
- annotator approves answer or requests corrrection
-
PixMo-Docs
- They used an extensive and carefully tuned prompting framework to prompt an LLM to generate code for 255k text and figure-heavy images, including charts, documents, tables, and diagrams. They then prompted the LLM to generate 2.3M question-answer pairs based on privileged access to the code (the images were not used).
-
PixMo-Count.
- They used a standard object detector on web images to create image and counting QA pairs.
- For each image, they selected the class with the most detections after strict confidence thresholding.
Molmo (model)
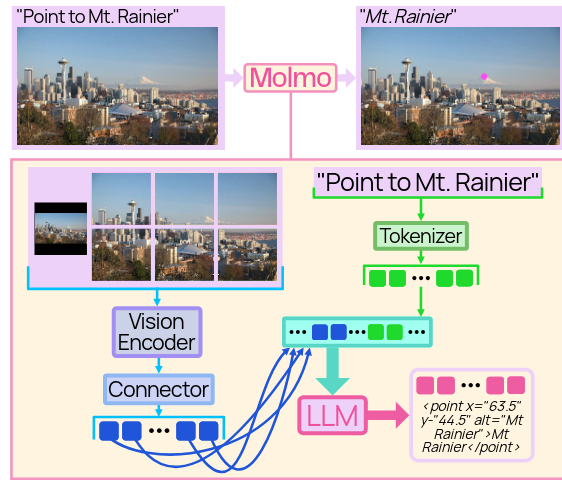
Architecture
It has four components:
- a pre-processor that converts the input image into multiscale, multi-crop images
- a ViT image encoder that computes per-patch features for each image independently
- a connector that pools and projects patch features into the LLM’s embedding space
- a decoder-only LLM
Image input handling (cropping)

-
They divide the image into multiple overlapping square crops that tile the image.
- The patches are 12x12 pixels
- The crops overlap by 4 patches or 46 pixels
- For the crops, they pad each crop with black borders such that the crops are square and the aspect ratio is preserved
-
Additionally, the full image, resized to the ViT’s resolution, provides a low-resolution overview. (also with black borders to preserve the aspect ratio)
-
Each crop is processed independently by the ViT.
-
A learned embedding is added to the patch features from each crop (before the connector is applied) depending on whether that patch includes no padding, some padding, or is all padding, so the model can distinguish padding from images that naturally have black borders.
Vision-language connector.
- Once crops are encoded by the vision encoder, they build patch features by concatenating features from the third-to-last and tenth-from-last ViT layers,
- which improves performance slightly over using a single layer.
- Each 2×2 patch window is then pooled into a single vector using a multi-headed attention layer, where the mean of the patches serves as the query. This attention pooling outperforms simple feature concatenation (see Sec- tion 6). Finally, pooled features are mapped to the LLM’s embedding space via an MLP
Arranging vision tokens.
Pooled patch features (vision tokens) are sequenced left-to-right, top-to-bottom, starting with patches from the low-resolution full image, followed by high-resolution crop patches arranged in row-major order. Special tokens are inserted to mark the start and end of both low- and high-resolution patch sequences, with row-end tokens added between rows to indicate row transitions.
Pretraining
- Pretraining is done on PixMo-Cap
- Previous work has often included a separate training stage to tune only the vision-language connectors. They found it not necessary.
- They apply a higher learning rate with a shorter warmup for the connector parameters, allowing them to adjust more quickly at the start of training.
- They train for four epochs using AdamW with a cosine learning rate decaying to 10% of its peak.
- Learning rates are set to 2e-4 (connector), 6e-6 (ViT), and 2e-5 (LM), with a 200-step warmup for the connector and 2000 steps for the ViT and LM.
Multi-annotated images
- Some images have multiple annotations (e.g. multiple questions-pairs for a single image)
- ⇒ sample packing
- we can encode the image once, pack all annotations together, and then mask attention between the different annotations
- reduces the number of processed images by two-thirds and shortening training time by over half, with only a 25% increase in sequence length for our data mix
- ⇒ sample packing
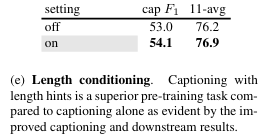
Captioning and length hints
- During pre-training, they train on each image paired with its caption and one of its audio transcripts.
- They use multi-annotation training (see Section C) to train on both the caption and the transcript jointly.
- They prompt the model with either
long_caption:or“transcript:”for captions and transcript respectively- (a natural language prompt is used instead during instruction fine-tuning)
- They also add a length hint: an integer providing a noisy hint as to the correct output length.
- They add the hint to the prompt 90% of the time, for example:
long_caption_83:for a length hint of 83, and 10% of the time no length hint is used to maintain the ability to output a default caption - This hint is computed as the length of the transcript/caption in characters, plus a noise factor drawn from a random normal with a standard deviation of 25. The hint is then divided by 15 and rounded down to keep the hint in roughly the range of 0 to 100.
- This noise is added so that the length functions more like a guideline than a hard constraint.
- For example, even with a long length hint, its preferable that a caption for a very plain image be short instead of becoming repetitive or inane due to lack of content to describe.
- They add the hint to the prompt 90% of the time, for example:
Finetuning
- They fine-tune the model on a mix of PixMo datasets and open-source training datasets.
- They sample datasets at rates proportional to the square root of their size, with manual down weighting of some very large synthetic datasets (PlotQA, FigureQA, DVQA, and PixMo-Clocks).
- They observe that pointing tasks learn more slowly than QA tasks, so they significantly up-weight the pointing data
- Academic datasets in this mixture teach specific skills and help the model perform well on corresponding benchmark test sets. However, these datasets often have answer styles that are not ideal for user interactions.
- To prevent these styles from affecting user-facing responses, they prompt the model with a task-specific style tag (e.g., prefixing VQA v2.0 questions with “vqa2:”).The model learns to use these styles only when requested.
Evaluation
Captioning metric (cap F1).
- They measure captioning quality, relative to an evaluation set of 15006 images, using the harmonic mean of captioning precision and recall, i.e. the F1 score.
- The evaluation set was gathered through a sim- ilar protocol as PixMo-Cap (selecting a small number of images matching a diverse set of categories), but the im- ages were selected manually and are disjoint from images in PixMo-Cap.
- Each evaluation image has up to six au- dio transcripts associated with it. To define the precision and recall of a caption for an image, let g be the generated caption and T be the set of ground-truth transcripts for the image.
- They prompt GPT-4o to enumerate a list of all distinct atomic statements contained in g and, separately, the transcripts in T .
- They then prompt GPT-4o to match each item in the list of atomic statements from g to items in the list of atomic statements from T .
- To compute recall, they consider matches as true positives, unmatched items from T ’s list as false negatives. , unmatched items from g as false positives.
- To compute precision, they prompt GPT-4o with the raw transcripts and the list of statements from g and ask it to say if each statement is consistent (a true positive) or inconsistent (a false positive) with the transcripts.
- (They avoid using the atomic statements from T when com- puting precision because it’s a potentially noisy processing step that is not necessary.)
- While this metric is imperfect (e.g., GPT-4o makes mis- takes, the transcripts do not contain all true statements about the image, etc.), they found that improvements to cap F1 corresponded to improvements in their subjective impressions of caption quality, and thus it was a useful internal metric for guiding model and data design.