Summary
-
Dreamer 4, a scalable agent that learns to solve control tasks by reinforcement learning inside of a fast and accurate world model.
-
Minecraft, the world model accurately predicts object interactions and game mechanics, outperforming previous world models by a large margin.
-
real-time interactive inference on a single GPU through a shortcut forcing objective and an efficient transformer architecture.
-
the world model learns general action conditioning from only a small amount of data, allowing it to extract the majority of its knowledge from diverse unlabeled videos
-
They propose the challenge of obtaining diamonds in Minecraft from only offline data, aligning with practical applications such as robotics where learning from environment interaction can be unsafe and slow
World Model Agent
- Dreamer 4 consists of a causal tokenizer and an interactive dynamics model
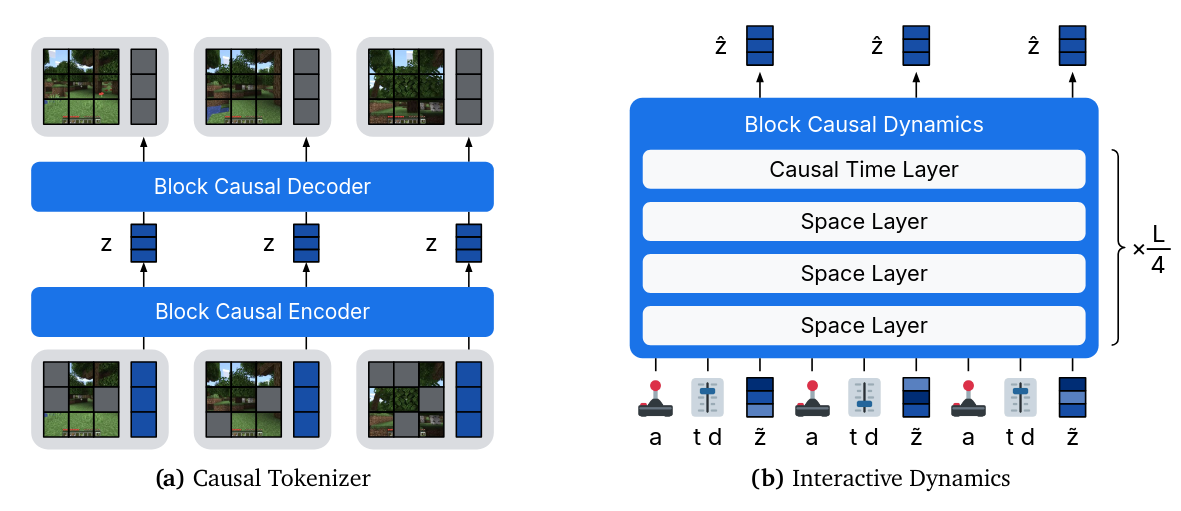
Causal Tokenizer
-
The tokenizer compresses raw video into a sequence of continuous representations for the dynamics model to consume and generate.
-
It consists of an encoder and a decoder with a bottleneck in between.
- Both components are causal in time, enabling temporal compression while maintaining the ability to decode frame by frame for interactive inference.
-
They use the efficient transformer architecture described later.
Input → Output
-
Each time step consists of patch tokens of the current image and learned latent tokens (i.e. learned embeddings for new modalities such as actions)
-
After applying the encoder, the representations are read out of the latent tokens using a linear projection to a smaller channel dimension followed by a tanh activation
-
For the decoder, this representation is projected back up to the model dimension and concatenated with learned tokens to read out the patches.
-
To flexibly integrate multiple input modalities if available, the encoder allows the latent tokens to attend to all modalities, while each modality only attends within itself. Correspondingly, each decoder modality attends within itself and to the latents, while the latents only attend within themselves.
Learning objective
-
They train the tokenizer using a straightforward reconstruction objective consisting of mean squared error and LPIPS loss.
-
They use masking, and drop out input patches with some probability $p \sim U(0,0.9).
Interactive dynamics model
-
The interactive dynamics model builds on top of Flow matching, Shortcut & Consistency models, and Diffusion Forcing.
-
The dynamics model operates on the interleaved sequence of actions and representations produced by the frozen tokenizer.
-
It is trained using a shortcut forcing objective to enable fast interactive inference with 𝐾 = 4 forward passes per generated frame
Architecture
-
The dynamics model uses the efficient transformer architecture on interleaved blocks of observations and actions .
-
The representations are linearly projected into
- spatial tokens
- concatenated with learned register tokens (i.e. attention sinks)
- concatenated with a single token for the shortcut signal level , and the step size .
- Since the signal level and step size are discrete, they encode each with a discrete embedding lookup and concatenate their channels.
-
Actions can contain multiple components, such as mouse and keyboard.
- They encode each action component separately into tokens (same number for each action)
- They then sum the results together with a learned embedding, to obtain the final tokens
- Continuous actions components (e.g. speed) are linearly projected and categorical or binary components (e.g. buttons) use an embedding lookup.
-
When training unlabeled videos, only the learned embedding is used
Shortcut forcing
- Combination of shortcut models & diffusion forcing
- shortcut models for fast generation
- diffusion forcing in this case, in order to slightly noise past inputs during inference to make the model robust to small imperfections in its generations.
Parameters of the diffusion model
The dynamics model takes the interleaved sequence of actions , discrete signal levels and step sizes , and corrupted representations as input and predicts the clean representations .
Note that is the sequence timestep (important for diffusion forcing) while is the signal level at that step. Thus, is a vector of length equal to the sequence.
Learning objective
-
Shortcut models parameterize the network to predict velocities called v-prediction.
- This approach excels when generating the output jointly as one block, such as for image or video generation models
- However, v-prediction trains the network to produce high-frequency outputs.
- (Bonus) why?
- because the target you predict contains a white-noise term. Let and be the spatial Fourier transforms of the clean sample and the Gaussian noise. Natural images have 1/f-like spectra (more power at low frequencies), whereas white noise has a flat spectrum
- Thus, the spectrum of the target has fatter bands than real images, and the network will learn high-frequency artifacts.
- (Bonus) why?
-
They found that parameterizing the network to predict clean representations , called x-prediction, enables high-quality rollouts of arbitrary length.
- Computing the flow loss term in x-space is straightforward.
- The bootstrap loss term for the shortcut model can computed by converting the network outputs into v-space, and scale the resulting loss back into x-space i.e.
- The network output is converted as . The MSE in x-space and v-space is related by , motivating a multiplier to bring the bootstrap loss into a range similar to the x-space flow loss.
- We compute the bootstrap terms
To focus the model capacity on signal levels with the most learning signal, they propose a ramp loss weight that linearly increases with the signal level 𝜏, where 𝜏 = 0 corresponds to full noise and 𝜏 = 1 to clean data:
Inference time
- At inference time, the dynamics model supports different noise patterns.
- They sample autoregressively in time and generate the representations of each frame using the shortcut model with sample steps with corresponding step size .
- They slightly corrupt the past inputs to the dynamics model to signal level to make the model robust to small imperfections in its generations.
Training recipe
Phase 1: World Model Pretraining
- Train tokenizers on videos
- Train world model on tokenized videos, and optionally actions.
Phase 2: Agent Finetuning
-
TLDR; finetune world model with task inputs for policy and reward head
-
Adding task conditioning To solve control tasks, they first adapt the pretrained world model to predict actions and rewards from the dataset conditioned on one of multiple tasks
- For this, they insert agent tokens as an additional modality into the world model transformer and interleave it with the image representations, actions, and register tokens
- Agent tokens are used as input to predict the policy and reward model using MLP heads.
- While the agent tokens attend to themselves and all other modalities, no other modalities can attend back to the agent tokens.
- This is crucial i.e. the prediction of the future state should solely be influenced by actions and previous state.
-
Behavior cloning and reward model
-
We need to initialize the task-conditioned policy and reward model.
-
We assume to have a datasets of videos that are encoded into representations , actions , tasks , and scalar rewards .
-
They train the policy and reward heads on the task output embeddings (obtained from the agent tokens) using multi-token prediction (MTP) of length .
- They parameterize the policy and reward heads using small MLPs with one output layer per MTP distance
- Following Dreamer 3, the reward head is parameterized as a symexp twohot output to robustly learn stochastic rewards across varying orders of magnitude
-
To preserve existing capabilities, they reuse the pretraining setting with this additional loss function, so the representations are noisy and they continue to apply the video prediction loss.
-
Phase 3: Imagination Pretraining
-
TLDR; Optimize policy head and value head on trajectories generated by the world model and the policy head. This is offline, no interaction with the environment needed.
-
What’s frozen or not
- They initialize a value head and a frozen copy of the policy head that serves as a behavioral prior.
- They only update the policy and value heads and keep the transformer frozen (it is possible to unfreeze it, but costly and requires additional losses)
-
Rollouts
- Imagined rollouts start from contexts of the dataset that was used during the earlier training phases.
- The rollouts are generated by unrolling the transformer with itself, sampling representations from the flow head and actions from the policy head.
- They annotate the resulting trajectories with rewards using the reward head and values using the value head.
-
Training the value head
- The value head is trained to predict the discounted sum of future rewards, allowing the policy to maximize rewards beyond the imagination horizon.
- It uses a symexp twohot output to robustly learn across different scales of values.
- They train the value head using temporal difference learning (TD-learning) to predict -returns computed from the predicted rewards and values along the sequence, where is a discount factor and indicates non-terminal states:
-
Training the policy head
- The policy head learns using PMPO a robust reinforcement learning objective that uses the sign of the advantages and ignores their magnitude.
- This property alleviates the need for normalizing returns or advantages and ensures equal focus on all tasks despite potentially differing return scales.
Efficient Tranformer - Model design
-
Need an efficient high-capacity architecture ⇒ used both by tokenizer and dynamics model
-
The base architecture is a 2D transformer, with time and space dimensions.
- causal attention for the time axis
- classics e.g. pre-layer RMSNorm, RoPE, SwiGLU, QKNorm, attention logit soft capping
- training objective is diffusion forcing with velocity parameterization.
- Has spatial tokens and sampling steps,
-
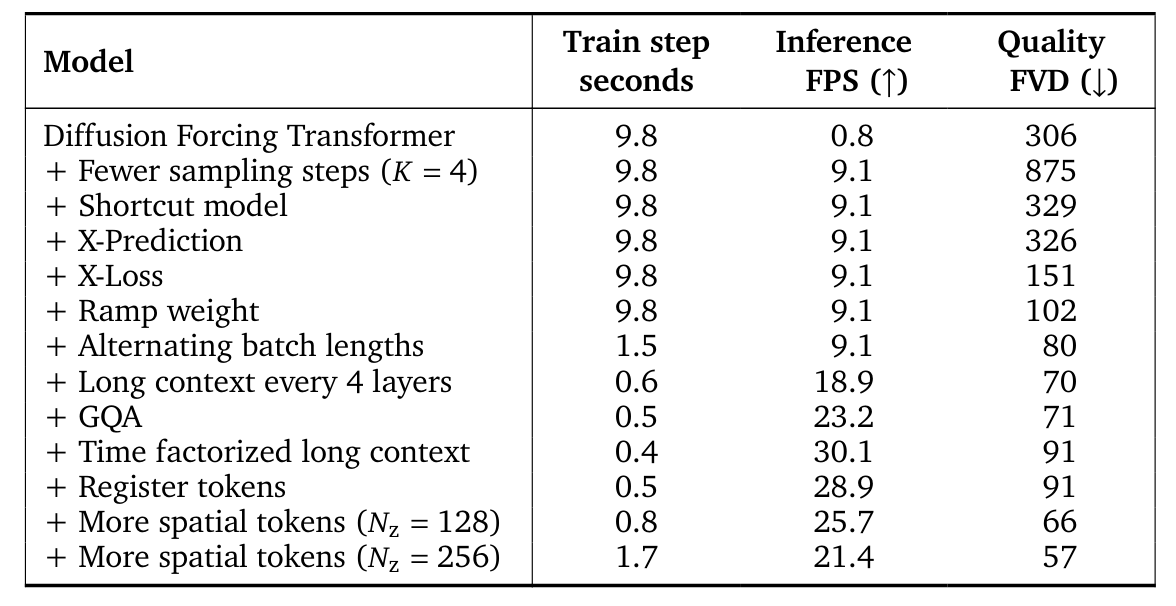
The target is 20 FPS interactive inference on a single H100 GPU, matching the tick rate of Minecraft and the framerate of the VPT dataset.
- With 64 sampling steps per frame, the baseline falls short of real-time generations with only 0.8 FPS on one H100 GPU, while 4 sampling steps achieve 9.1 FPS but result in poor quality
-
To ablate different choices,
- they train for 48 hours and then generate 1024 videos of 384 frames (~20 seconds) each without any context, with interactive actions chosen by a fixed behavioral cloning policy.
- They then split the resulting videos into 16 frame chunks to compute the Fréchet Video Distance (FVD) to the holdout dataset.
-
Training changes
- Shortcut models nearly recover the original visual quality with only 4 sampling steps
-
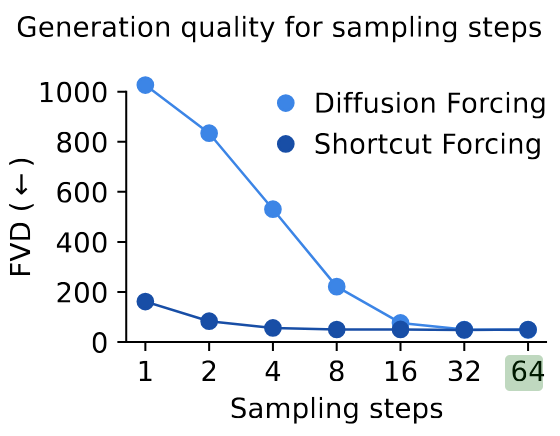
- Parameterize the model to make x-space predictions, compute the loss in x-space, and apply the ramp loss weight ⇒ hypothetoze that x-space targets are more structured, with less high-frequency artifacts
- Training on alternating batch lengths is similar to progressive training and speeds up learning while allowing to generate long videos for inspection throughout training ⇒ sometimes, add batchs with longer context that the model is usually trained on.
- Shortcut models nearly recover the original visual quality with only 4 sampling steps
-
-
Architecture changes
- break up the cost of dense attention over all video tokens by using separate space-only and time-only attention layers
- ⇒ allows to use more tokens
- Only a relatively small number of temporal layers are needed and only use temporal attention once every 4 layers
- ⇒ also improves generation quality (possibly because of the inductive bias of spatial attention that focuses computation on the current frame)
- GQA, because faster sampling and no degradation.
- The register tokens do not improve FVD measurably, we qualitatively notice that they improve temporal consistency
- After these changes, training and inference is fast enough
- we can increase model capacity through more spatial tokens (i.e. image tokens)
- break up the cost of dense attention over all video tokens by using separate space-only and time-only attention layers
Next steps
- Training on general internet videos
- Integrating long-term memory
- Add language understsanding