- During training,
- Modality Encoder, LLM Backbone, and Modality Generator are generally maintained in a frozen state.
- The primary optimization emphasis is on Input and Output Projectors.
- Given that Projectors are lightweight components, the proportion of trainable parameters in MM-LLMs is notably small compared to the total parameter count (typically around 2%).
General architecture components
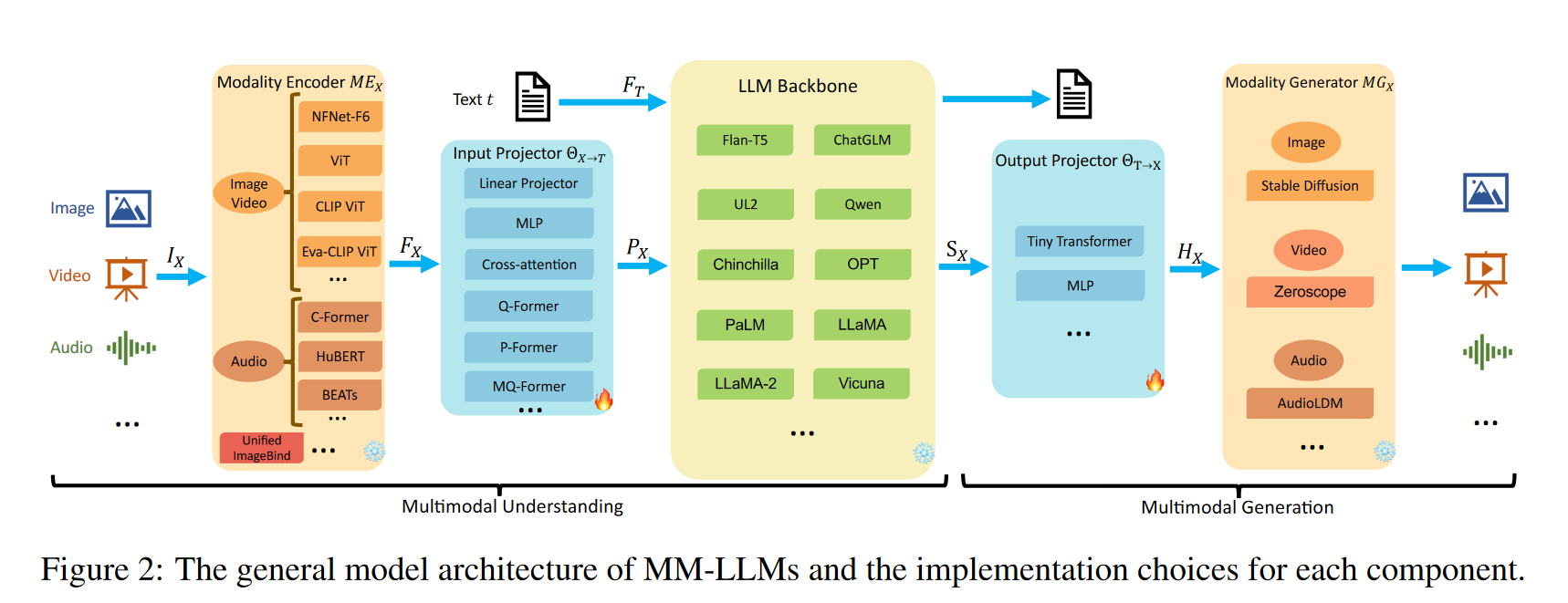
Modality Encoder
-
, we want to extract features
-
Vision: CLIP, SigLip
-
Audio: Whisper, CLAP
-
ImageBind: joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data.
- allows for multimodal-conditioned generation
- aligns each modality’s embeddings to the image embeddings (potentially extracted from CLIP)
- no explicitly aligned pseudo-labeled dataset

Input Projector
- The Input Projector is tasked with aligning the encoded features of other modalities with the text feature space . The aligned features as prompts are then fed into the LLM Backbone alongside the textual features .
- Given -text dataset , the goal is to minimize the -conditioned text generation loss
- If we’re also generating the modality i.e. , the the loss becomes
LLM backbone
- It produces (1) direct textual outputs t, and (2) signal tokens from other modalities (if any).
- These signal tokens act as instructions to guide the generator on whether to produce MM contents
Output Projector
- The Output Projector maps the signal token representations from the LLM Backbone into features understandable to the following Modality Generator .
- Given -text dataset , is first fed into LLM to generate the corresponding , then mapped into
- To facilitate alignment of the mapped features , the goal is to minimize the distance between and the conditional text representations of :
- is the textual condition encoder in
- To facilitate alignment of the mapped features , the goal is to minimize the distance between and the conditional text representations of :
Modality Decoder/Generator
- The Modality Generator is tasked with producing outputs in distinct modalities.
- Need to able to parse LLM response if the response is text only i.e. H_X is the identity
- Common:
- Stable Diffusion (image)
- Zeroscope, Videofusion (video)
- AudioLDM-2 (audio)
- Can also compute text-conditioned noise-matching loss to tune the input and output projectors