Resources
-
https://pytorch.org/executorch/stable/compiler-delegate-and-partitioner.html
-
https://pytorch.org/executorch/stable/backend-delegates-integration.html
-
Good coding examples are in https://github.com/pytorch/executorch/tree/main/exir/backend/test
Summary
- A delegate backend implementation is composed of:
- An ahead-of-time preprocessing interface
- program preprocessing (e.g. ahead of time compilation, transformation, optimization…).
- e.g. for XNNPACK, this is where you define the
xnn_subgraphand compile it withxnn_create_runtime
- e.g. for XNNPACK, this is where you define the
- program preprocessing (e.g. ahead of time compilation, transformation, optimization…).
- A runtime initialization and execution interface
- Program initialization (e.g. runtime compilation).
- e.g. for XNNPACK, this is where you call
reshape_runtimeandsetup_runtime
- e.g. for XNNPACK, this is where you call
- Program execution.
- e.g. for XNNPACK, this is
invoke_runtime
- e.g. for XNNPACK, this is
- (optional) Program destroy (e.g. release backend owned resource)
- Program initialization (e.g. runtime compilation).
- An ahead-of-time preprocessing interface
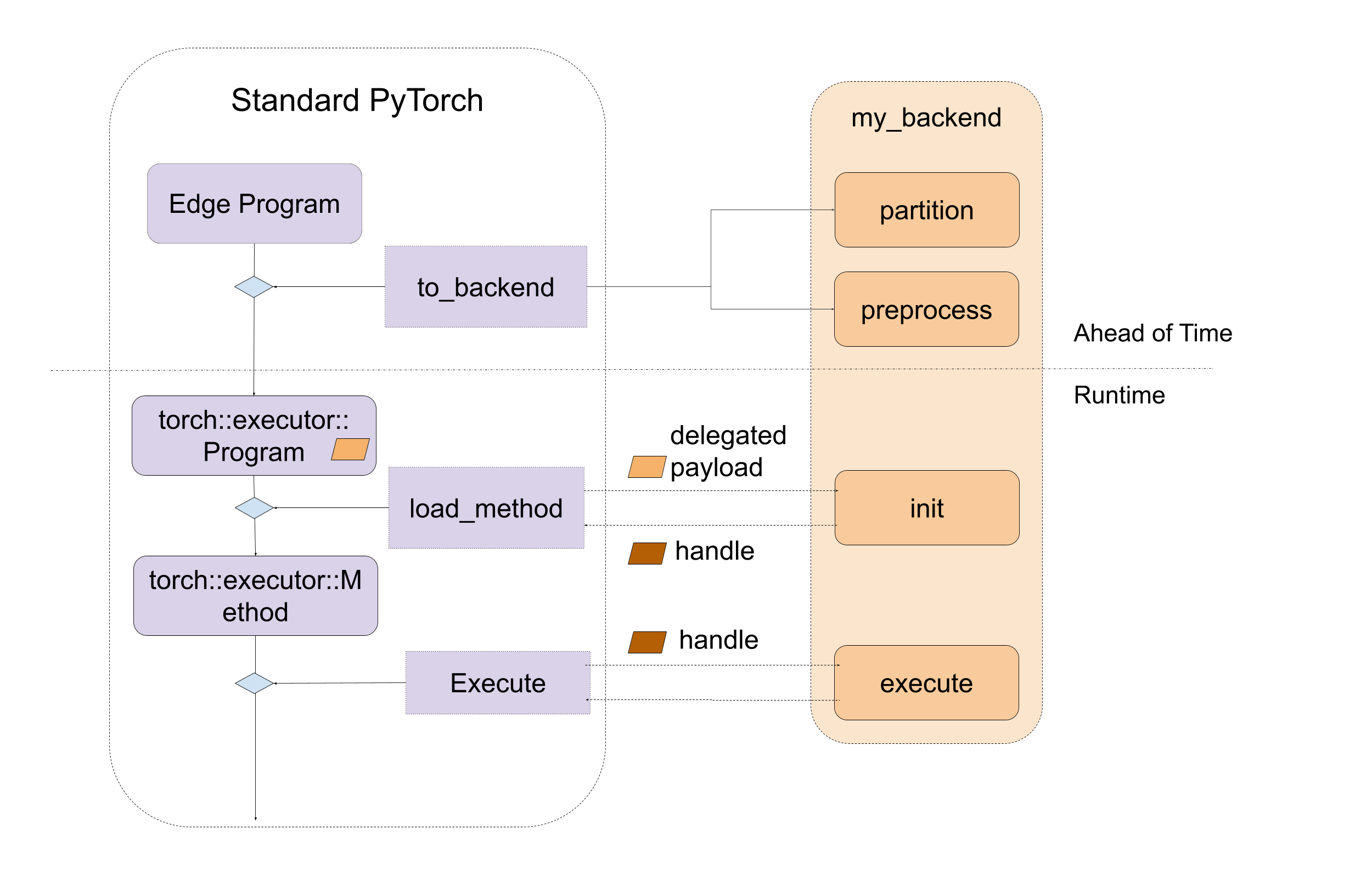
- You will need to implement in
executorch/backends/<delegate_name>/the Python sources files forpreprocess()andpartition()for ExecuTorch AOT flow. - You’ll also need to implement the C++ files for defining the Executor for
init()andexecute()
Backend interfaces:
Ahead-of-Time Preprocessing
- There are mainly two Ahead-of-Time entry point for backend to implement:
partitionandpreprocess.
partitioneris an algorithm implemented by the backend to tag the nodes to be lowered to the backend.- Every tagged subgraph will be sent to the
preprocesspart provided by the backend to compiled as a binary blob.
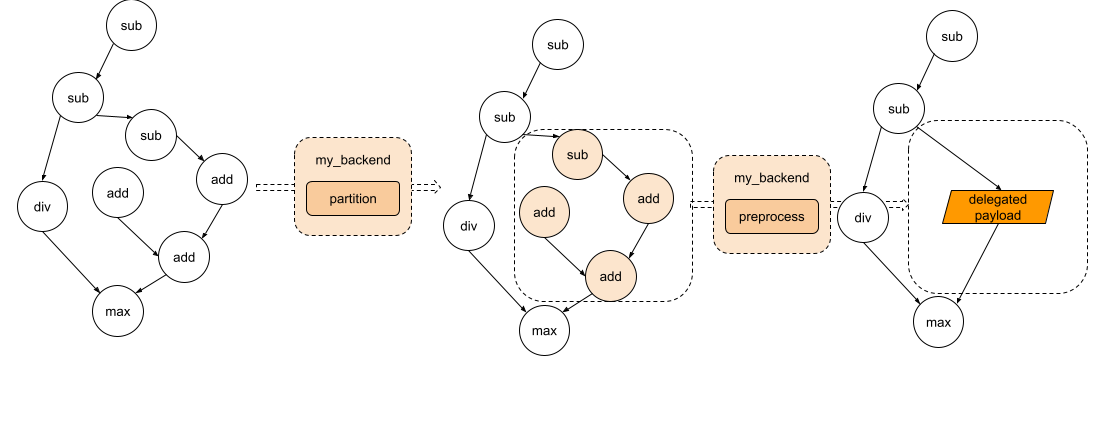
The partitioner
- The main API looks like this
@dataclass
class PartitionResult:
tagged_exported_program: ExportedProgram
partition_tags: Dict[str, DelegationSpec]
def partition(
exported_program: ExportedProgram,
) -> PartitionResult:
- The nodes that intend to be delegated must be tagged (by setting
node.meta["delegation_tag"]) and this tag must be provided in thepartition_tagsdictionary mapping to an instance ofDelegationSpec(backend_id, method_compilation_spec). - Each tag must represent a distinct submodule that we intend on lowering and should be fully contained.
The preprocesser
- The Main API looks like this
@dataclass
class PreprocessResult:
processed_bytes: bytes = bytes()
debug_handle_map: Optional[Union[Dict[int, Tuple[int]], Dict[str, Tuple[int]]]]
def preprocess(edge_program: ExportedProgram,
compile_specs: List[CompileSpec]) -> PreprocessResultRuntime Initialization and Execution
- During the runtime, the compiled blob from the
preprocessfunction will be loaded and passed directly to the backend’s custominitfunction. - The backend’s custom
executefunction will then be called to execute the handle produced byinit - The main API looks like this:
// Runtime initialization
ET_NODISCARD virtual Result<DelegateHandle*> init(
BackendInitContext& context,
FreeableBuffer* processed,
ArrayRef<CompileSpec> compile_specs);
// Runtime execution
ET_NODISCARD virtual Error execute(
BackendExecutionContext& context,
DelegateHandle* handle,
EValue** args);