-
Fork to improve FSDP
- give it better memory allocation to save memory (FSDP can over-allocate)
- reduce idle time in computation and communication stream
 Showcase of idle time because of many small operations in 3-5 CUDA streams.
Showcase of idle time because of many small operations in 3-5 CUDA streams.
Improvements
Buffers (memory allocation)
- Like FSDP, they shard layers instead of individual parameters, to maintain efficient communications (keep the data bus busy)
- To control memory consumption, they allocate buffers for all required data in advance to avoid letting Torch take care of it.
Buffer implementation
- On a given process, two buffers are allocated for storing intermediate weights and gradients.
- Each odd layer uses the first buffer, and each even layer uses the second buffer.
- This way, the GPU can compute using the parameter/gradients of its current layer, while concurrently fetching for the next layer. Thus, it’s non-blocking.
Buffers for what
- Buffers to store shards and gradients in
fp32for the optimizer (mixed-precision) - A buffer to store the weight shard in half precision (`bf16/fp16)
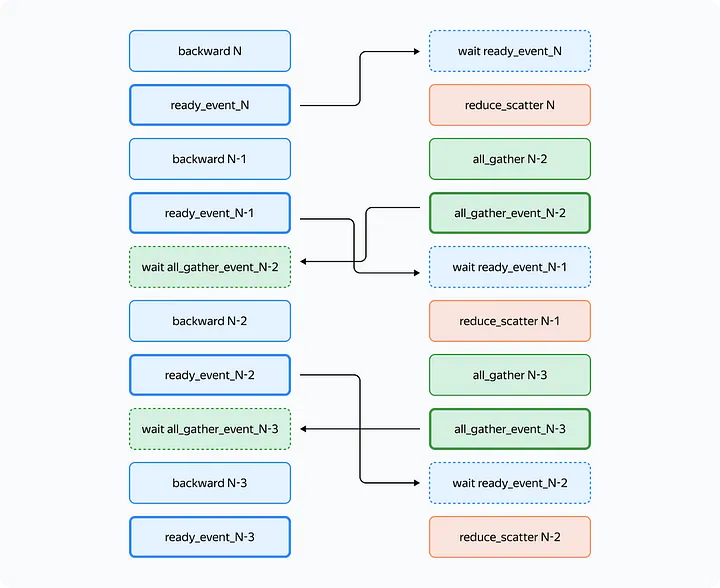
Communications requirements
- Set up communications so that:
- The forward/backward pass on the layer doesn’t start until the weights of that layer are collected in its buffer.
- Before the forward/backward pass on a certain layer is completed, we don’t collect another layer in this layer’s buffer.
- The backward pass on the layer doesn’t start until the reduce_scatter operation on the previous layer that uses the same gradient buffer is completed.
- The reduce_scatter operation in the buffer doesn’t start until the backward pass on the corresponding layer is completed.
Overlapping communication and computation
- They use CUDA streams (1 computation stream and 1 communication stream) and use CUDA events to handle synchronization requirements
- To satisfy requirements 1 and 2 above, you can use this sequence of events
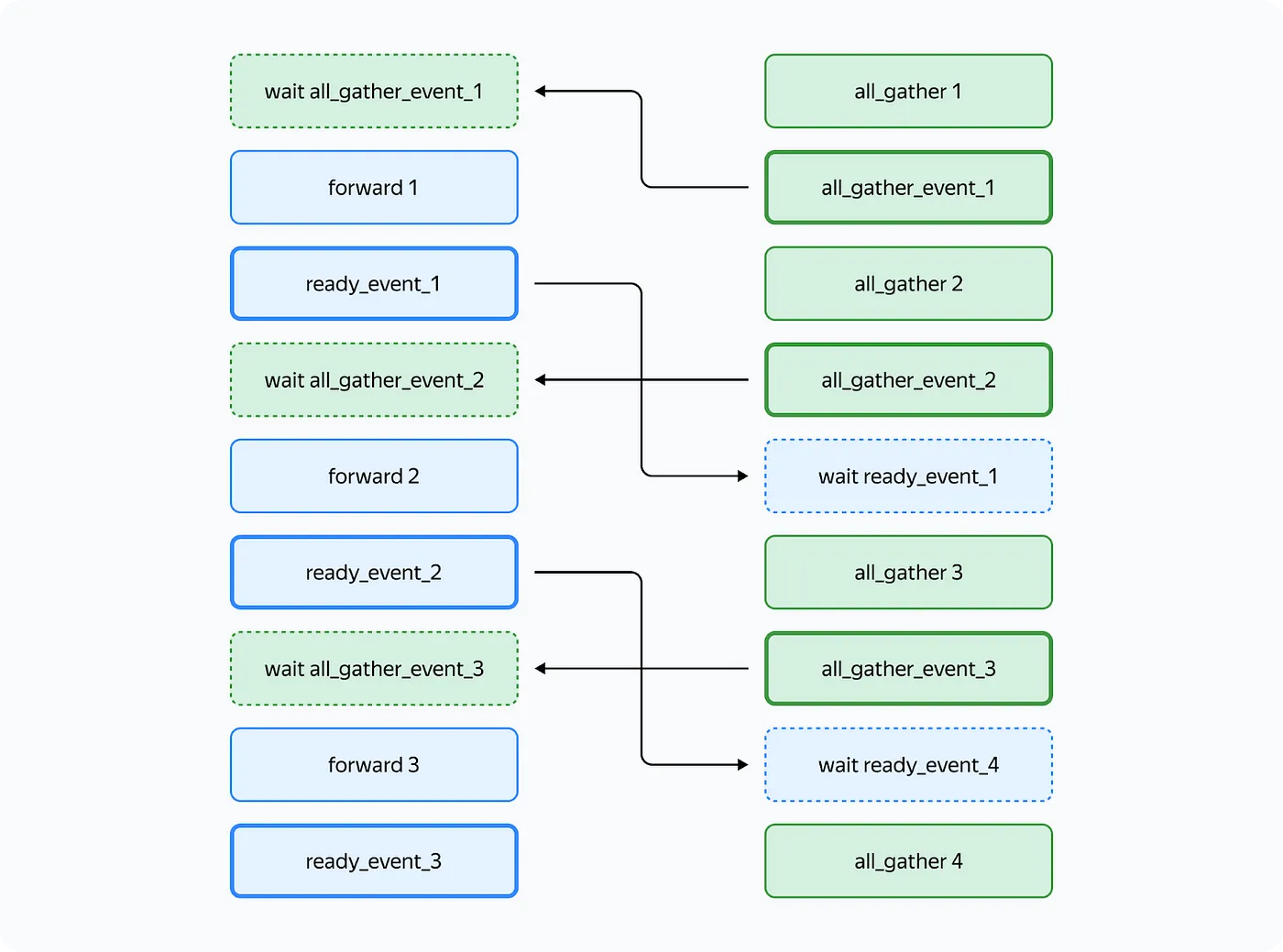
- Bold =
event.record(), dotted =event.wait()
How to implement in Torch
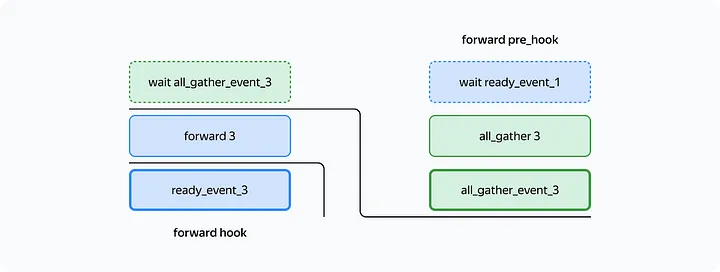
Forward
- You can use
forward_pre_hookandforward_hook
Backward
- CUDA stream events
- Caveat
- While
backward_pre_hookworks exactly as anticipated,backward_hookmay behave unexpectedly:- If the module input tensor has at least one tensor that doesn’t pass gradients (for example, the attention mask),
backward_hookwill run before the backward pass is executed. - Even if all module input tensors pass gradients, there is no guarantee that
backward_hookwill run after the.gradof all tensors is computed.
- If the module input tensor has at least one tensor that doesn’t pass gradients (for example, the attention mask),
- While