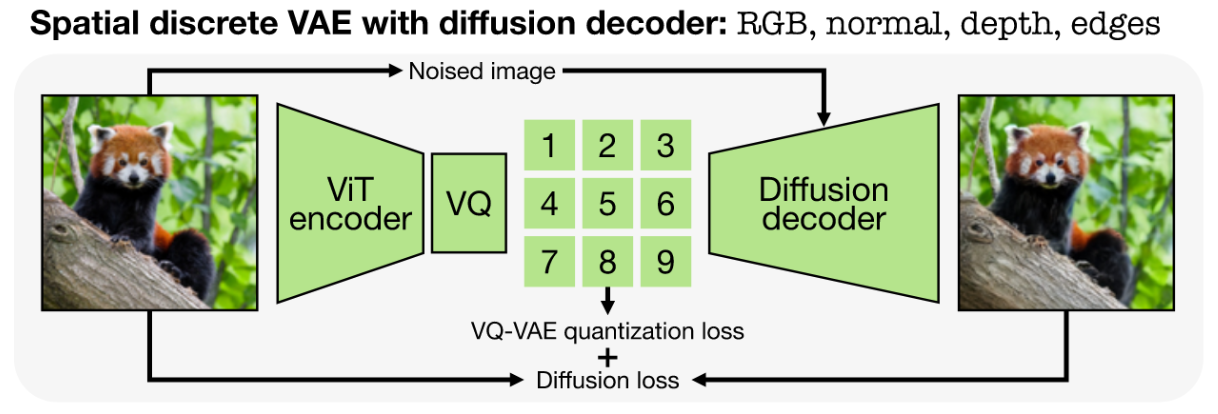
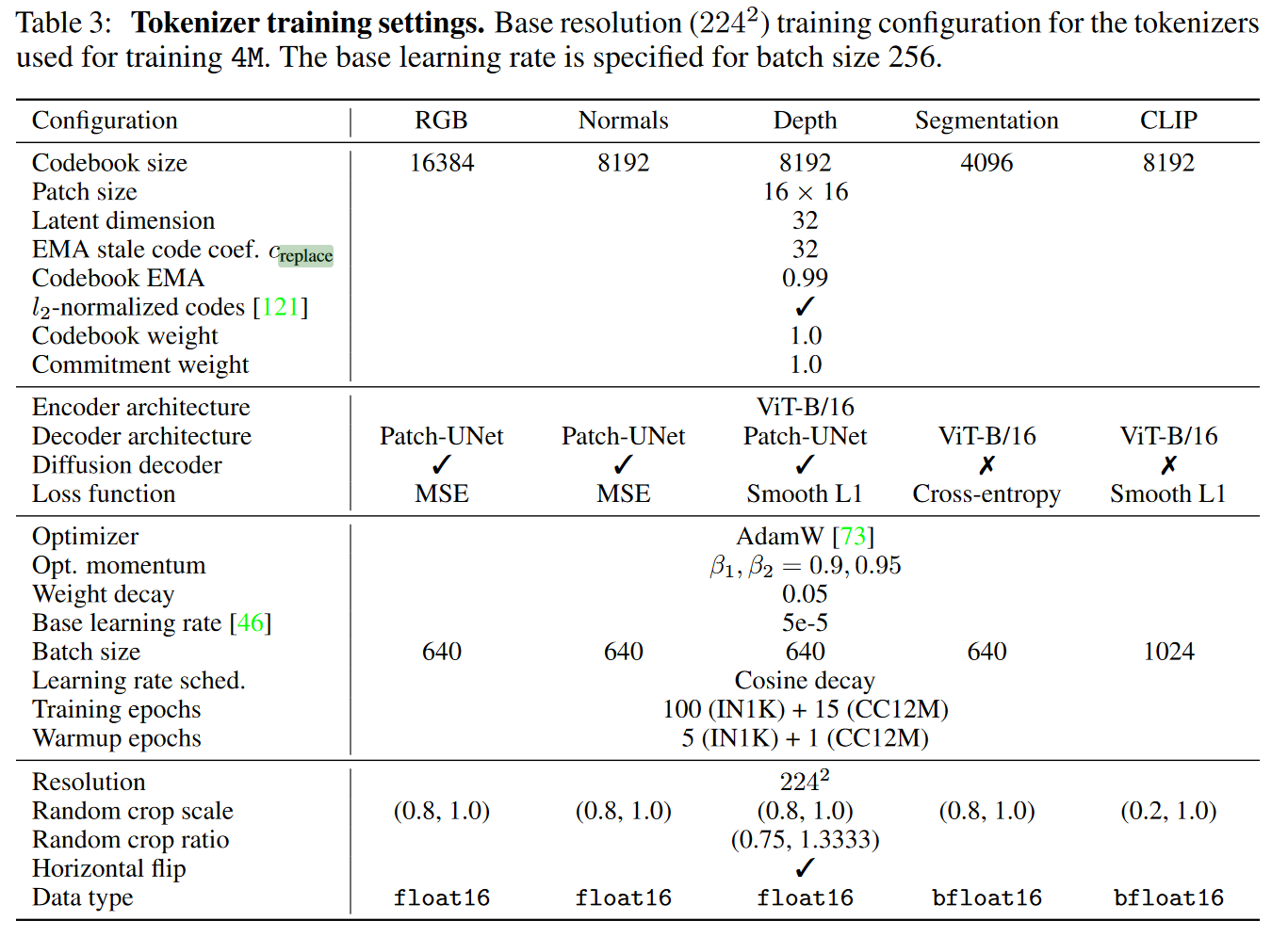
They follow guidelines from “Vector-quantized image modeling with improved VQGAN” and “SoundStream: An end-to-end neural audio codec”
Switching from CNNs to ViT
Replace the CNN encoder/decoder by a ViT.
Given sufficient data (for which unlabeled image data is plentiful), ViT VQ-VAE is less constrained by the inductive priors imposed by convolution
Low codebook usage fixes
Vanilla VQ-GANs usually suffer from low codebook usage due to the poor initialization of the codebook.
During training a significant portion of codes are rarely used, or dead.
Can also lead to joint VQ-VAE and diffusion training collapse.
There are three improvements that can significantly encourage the codebook usage even with a larger codebook size of 8192
Factorized codes / reducing the latent space size during lookup
Introduce a linear projection from the output of the encoder to a low-dimensional latent variable space for code index lookup (e.g., reduced from a 768-d vector to a 32-d or 8-d vector per code)
i,e. reduce the latent dimension when calculating nearest neighbour in the latent embedding space vocab. q(z=k∣x)=1[k=argminj∣∣P(ze(x))−P(ej)∣∣2] where P is the linear projector to reduce dimensionality.
l2-normalized codes
Apply l2 normalization on the encoded latent variables ze(x) and codebook latent variables e. The codebook variables are initialized from a normal distribution.
Additional component to keep the volume from expanding
Restarting stale codebook entries.
count the number of encoded vectors in a batch that map to a given codebook entry after every iteration
replace (randomly from the batch) any codes that have an exponential moving average (EMA) count less than a specified threshold threshreplace.
This value depends on the total batch size B, number of tokens per image Ntokens, and codebook vocabulary size Nvocab,
Given creplace, then threshreplace=creplaceNvocabBNtokens
The coefficient creplace means that a codebook entry should appear at least with probability creplace1, assuming we have mapped Nvocab encoded vectors.