- “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”
Summary
-
Main idea of the paper: “Given the current landscape of transfer learning for NLP, what works best? And how far can we push the tools we already have?”
-
T5 = “Text-to-Text Transfer Transformer
-
Generalizes all NLP task to a text-to-text framework
- Results in instruction-following tasks
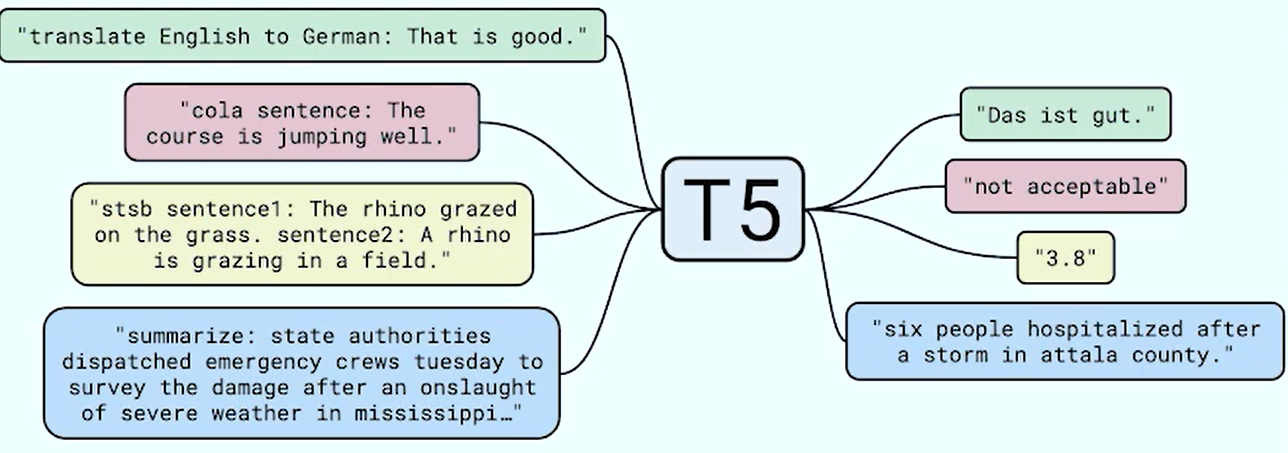
- unifies everything (loss, architecture, learning rate) for all tasks
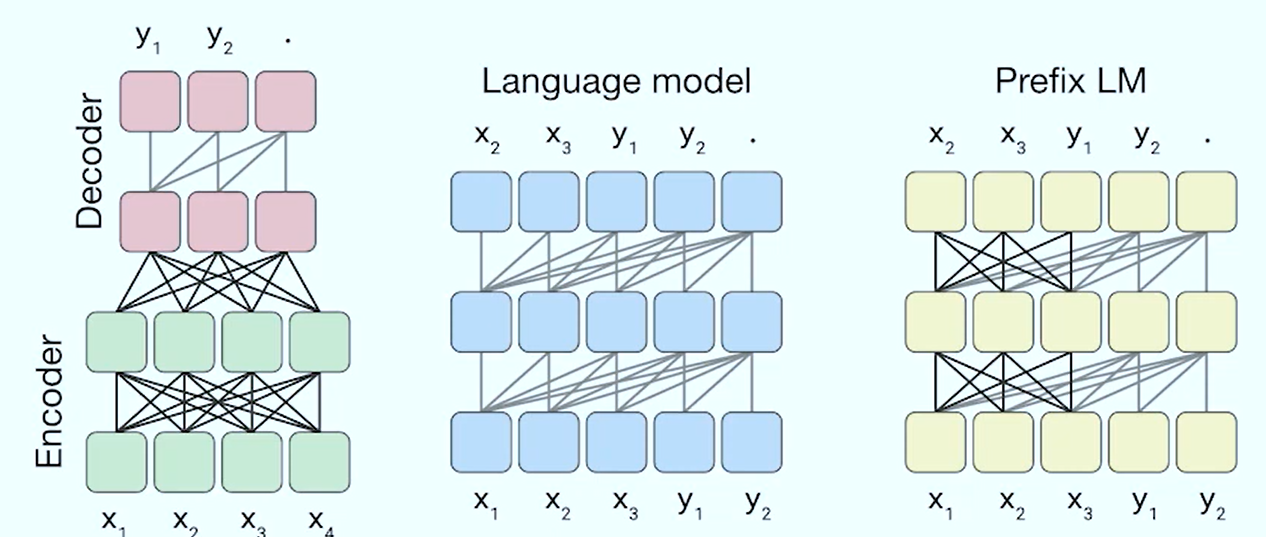
Architectures
- Baseline: Classic encoder-decoder, uses relative positional embeddings + RMSNorm
- Causal
- Prefix-LM
Pretraining Data
- Grabbed data from Common Crawl Web Extracted Text
- Applied heuristic filtering to it
- Remove any line that doesn’t end with a punctuation
- Removed any curly bracket (remove code)
- Remove “javascript”
- deduplication
- keeping only english text
- Resulted in (colossal, cleaned crawled corpus)
Unsupervised objectives
General view
-
BERT-style objective (masked modeling) works best for encoder-decoder model
-
They investigate different variations denoising objective
-

-
They conclude that BERT-style objectives are better
- More specifically, span corruption is generally the best
Span corruption
- very scalable objective because you don’t have to deal with the whole sequence at input and output time.
- How it works
- drop out tokens in the sequence
- replace each SPAN of dropped tokens by a single sentinel token
- the objective for the model is to predict the spans of dropped out tokens
- the model has to decide how many tokens to predict for a given span

Implementation
- https://huggingface.co/docs/transformers/model_doc/t5
- The input of the encoder is the corrupted sentence
- The target is then the dropped out tokens delimited by their sentinel tokens.
- The input of the decoder is the target, shifted by right, to have the decoder_start_token_id at the beginning
- With those inputs, it’s basically next-token predicition
input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
labels = tokenizer("<extra_id_0> cute dog <extra_id_1> the <extra_id_2>", return_tensors="pt").input_ids
# the forward function automatically creates the correct decoder_input_ids
loss = model(input_ids=input_ids, labels=labels).loss- How does it create the
decoder_input_idsdecoder_input_ids = self._shift_right(labels)- https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py#L871
decoder_input_idshas the same shape aslabels- it’s
labelsbut shifted by the right to append thedecoder_start_token_id(and thus the last token of labels is cropped out)
- it’s
Corruption rate
- 15% to 25% is good.
Conclusion
- Use an objective that results in short target sequences ⇒ cheaper to do training.
General experimental procedure
- Setup a baseline over which we’ll be able to do ablations
Pretrain
Baseline model
- Bert-Base sized encoder-decoder transformer
- Denoising objective
- C4 Dataset
- Training
- steps on batch size of around tokens
- or ~ tokens
- Inverse square root learning rate schedule
Finetune
- ~ tokens
- Constant learning rate
Evaluation
- Evaluate all checkpoints, choose the best
- ”early stopping”, because some of the finetuning datasets don’t need to be finetuned for so many steps
How they do ablations
- Fix a reference baseline (i.e. the one defined above)
- Run it 10 times with different seeds ⇒ compute average and standard deviation
- you can assume that it’s okay to reuse the standard deviation across different ablations (usually we’re trying to capture the std of the task we’re evaluating, as it tends to be more significant than the model std)
- Tune the hyper-parameters with the baseline once (lr, betas, …)
- reuse them across all ablations
- Ablations should now be 2 standard deviations away to be considered to have a significant effect
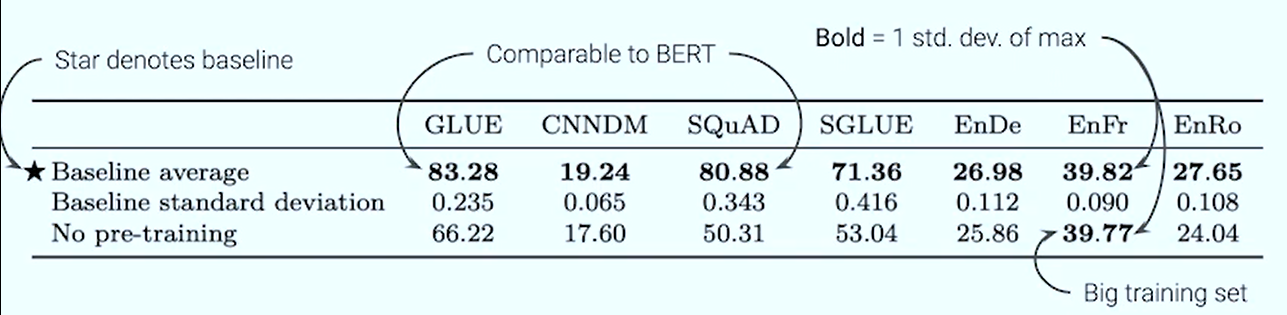
Results
Architecture comparison results

- Enc-dec shared, means all the parameters are exactly the same, except for the cross-attention block
Pretraining datasets comparison results
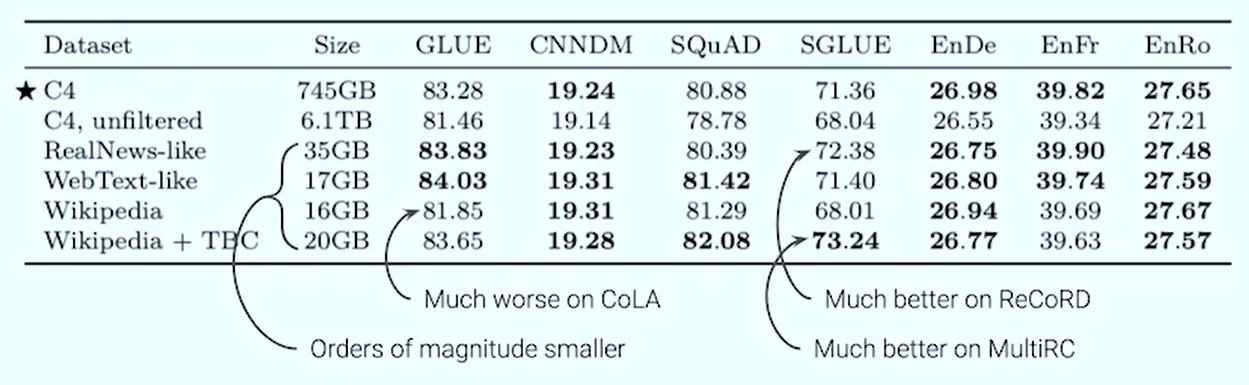
- Pretraining on in-domain data helps on downstream tasks
- For generalist model, scale is probably still the best choice
- Caveat: this is on smallish model with fixed training length
Scaling question
- Premise: You’re given 4 times more compute, how should you use it ?
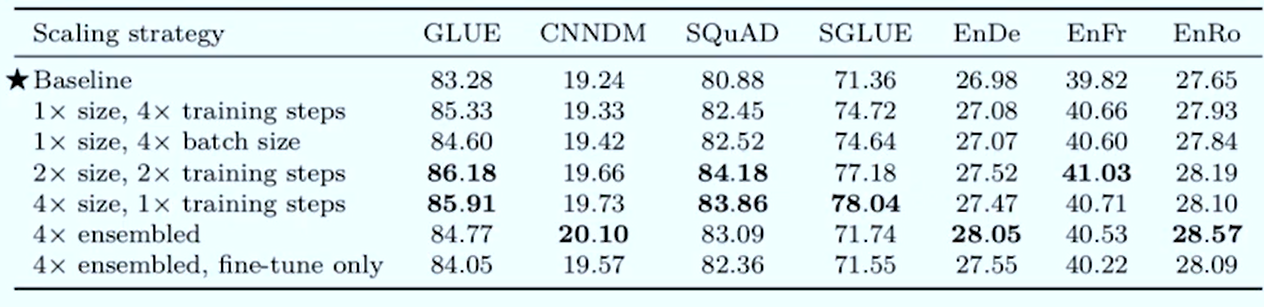
Big scaling
- Using:
- encoder-decoder
- span prediction objective
- C4 dataset
- multi-task pre-training
- not because it’s better than unsupervised pre-training, but because it allows you to monitor your model performance throughout training (as training runs take 1,2 weeks to train)
- Bigger model, trained for longer.
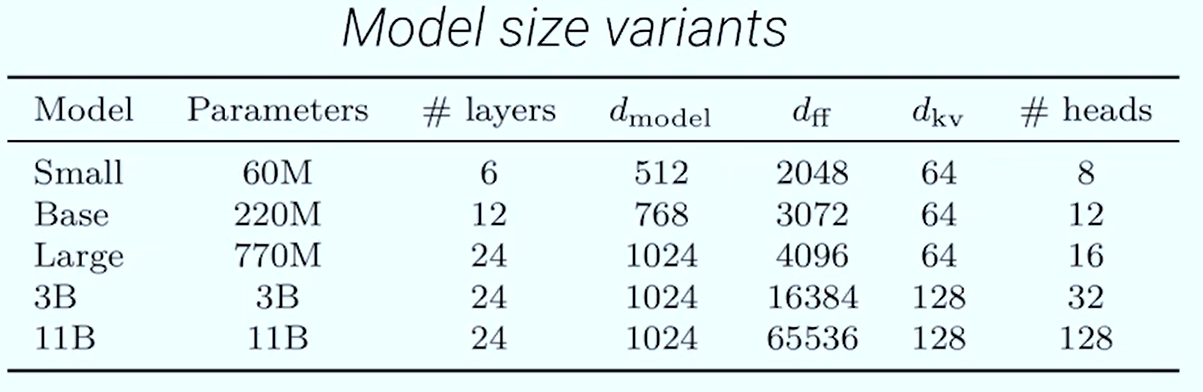
- Just make the feed-forward much much wider, very naive way to make your model bigger
- T5-11B gets SOTA on all tasks.