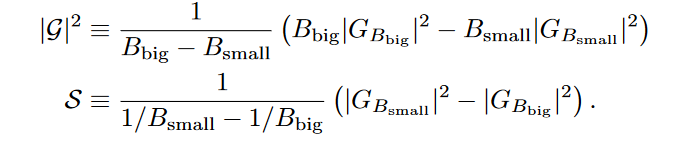“An Empirical Model of Large-Batch Training”
Takeaways
-
The gradient noise scale (essentially a measure of the signal-to-noise ratio of gradient across training examples) predicts the largest useful batch size across many domains and applications
-
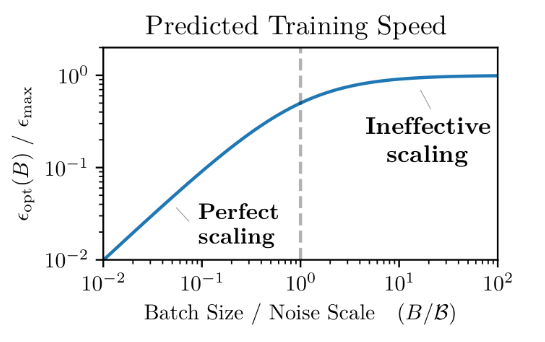
Best-tradeoff for efficiency is to select
-
Noise scale growth over training: will grow when the gradient decreases in magnitude, as long as the noise stays roughly constant. Since decreases as we approach the minimum of a smooth loss, we would expect B to increase during neural network training.
- The optimal learning rate initially scales linearly as we increase the batch size. For Adam and RMSProp, the optimal learning rate initially obeys a power law with between and depending on the task,
- Early in training, smaller batches are sufficient to make optimal progress, while larger batches are required later in training.
-
Why it matters:
- A major enabler in the growth of DL has been parallelism – the extent to which a training process can be usefully spread across multiple devices. Regardless of how much total computation is available, if model training cannot be sufficiently parallelized, then it may take too much serial time and therefore may be practically infeasible
- Common source of parallelism: data parallelism
- Large batch sizes can achieve almost linear speed-ups in training without substantially harming sample efficiency or generalization.
- A major enabler in the growth of DL has been parallelism – the extent to which a training process can be usefully spread across multiple devices. Regardless of how much total computation is available, if model training cannot be sufficiently parallelized, then it may take too much serial time and therefore may be practically infeasible
-
Why is there an optimal batch size?
- Set up: SGD optimization
- If batch size very small
- The gradient approximation will have very high variance, and the update will be mostly noise
- Over many updates, the noise will wash out
- However, this requires many sequential steps
- We can get a linear gain in efficiency by parallelizing i.e. increasing the batch size and get an equivalent results, by aggregating those small updates and applying them all at once (by increasing batch size and learning rate)
- If batch size very big
- The gradient approximation is equal to the true gradient
- However, reducing the batch size by two will likely give us the same approximation
- Thus, we’re using twice as much computation for little gain
- The optimal batch size gives us a good (not too noisy) gradient approximation, while being compute efficient.
-
Smaller batch size may helpful to escape local minimas, as the noise in the estimated gradient will get us out of it
Definition of gradient noise scale
Summary
- Gradient noise scale = the noise scale is equal to the sum of the variances of the individual gradient components, divided by the global norm of the gradient
- The optimal improvement of the loss from the noisy gradient update is a function of and i.e.
- In this way, we can compute when we get diminishing returns from increasing batch size, the conclusion is that batch size should roughly equal the noise scale
Detailed
-
Consider a model, parameterized by variables , whose performance is assessed by a loss function . The loss function is given by an average over a distribution over data points . Each data point has an associated loss function , and the full loss is given by
-
The true gradient is
-
Estimated gradient:
-
is a random variable such that
- =
-
- where the per-example covariance matrix of the gradient
-
We are interested in how useful the gradient is for optimization purposes as a function of , and how that might guide us in choosing a good .
-
We can do this by connecting the noise in the gradient to the maximum improvement in true loss that we can expect from a single gradient update.
-
Letting and be the true gradient and hessian at parameters
- We can perturb the parameters by a small vector to , where is the step size
- We do a quadratic Taylor expansion of the loss around this perturbation
- Now if we replace by , we get on expectation
- for the trace term, remember that the scalar
- Let’s minimize this equation w.r.t
- where , the optimal step size given the true gradient
- and is the gradient noise scale
- Big assumption, if we assume the optimization is perfectly well-conditioned, then the hessian is a multiple of the identity matrix .
- then, we can compute a simple estimate of the gradient noise scale which is the the sum of the variances of the individual gradient components divided by the norm of the gradient.
How to compute the gradient noise scale in practice
- There’s a a method for measuring the noise scale that comes essentially for free in a data-parallel training environment
- We estimate the noise scale by comparing the norm of the gradient for different batch sizes
Derivation
- The expected gradient norm norm for a batch size is
- Given estimates of for both and , we can obtain unbiased estimates of and for and , respectively
- We can compute and for free in a data-parallel method by computing the norm of the gradient before and after averaging between devices :)))
- Note that is not an unbiased estimator of
- Thus, we keep an EMA of both values such that the ratio of the moving averages is a good estimator of the noise scale.