From Ring Attention: “With a batch size of 1, processing 100 million tokens requires over 1000GB for a modest model with a hidden size of 1024”.
Input has to be materialized
Memory scales linearly with Flash-Attention (compute is still quadratic)
need to store input QKV + output + LSE + dout for backward
Vanilla Attention
Memory complexity of naive attention is quadratic with sequence length (attention matrix & softmax output)
The crux of Attention: softmax
s(xi)=∑j=1nexjexi
Challenge: you need to know the denominator D i.e. full sums over rows of the score matrix S=QKT
For FlashAttention & RingAttention, we need to compute the softmax part blockwise/online i.e. with parts of this sum!
Numerically stable softmax
remove the max from the row, more numerically stable
softmax is shift-invariant
Also, we do divisions as substractions in log-space! (much faster and stable)
Blockwise softmax
Each block computes a part of the denominator D i.e. Dk=∑j=(k−1)∗bkbexj
usually exchanged as log(Dk) i.e. log-sum-exp
Internal flash attention returns the log-sum-exp
You can then incrementally build up the denominator by adding the log-sum-exp
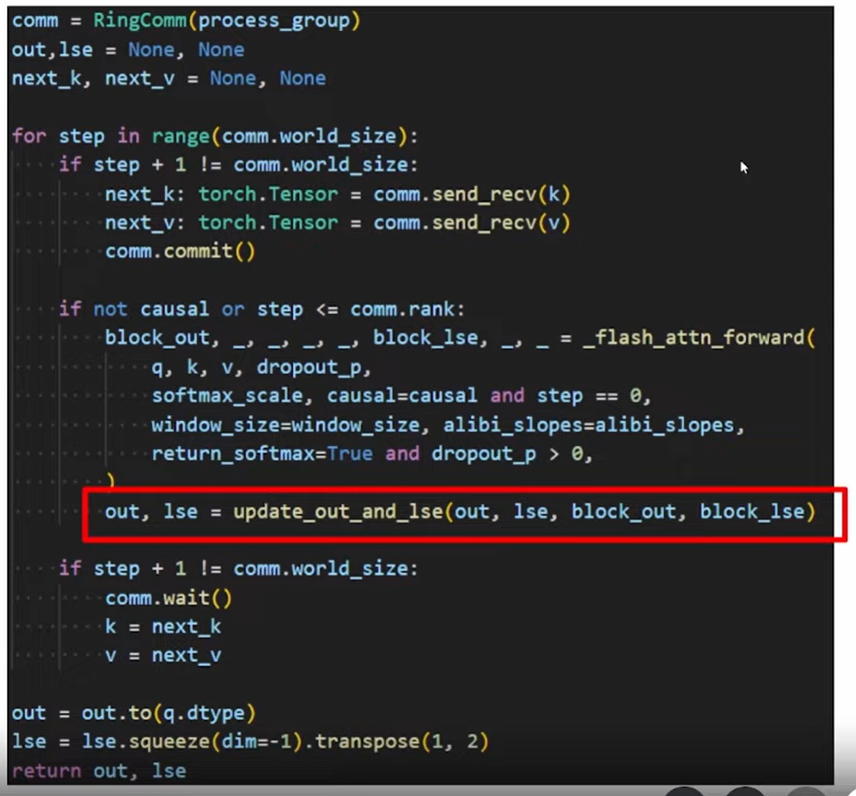
Code
accumulate into out variable
Ring Attention
For a given block of the query matrix Q e.g. Qk, Qk needs to see all the other blocks of K and V to output the correct attention
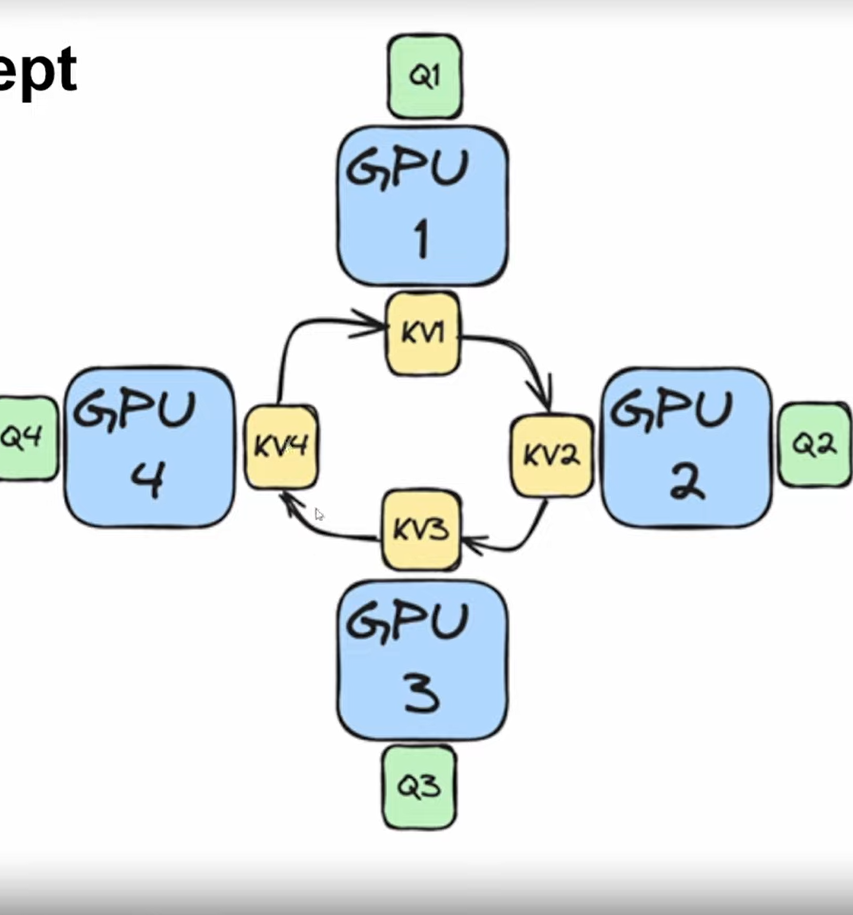
So we split QKV sequence across N devices
hosts form a conceptual ring to exchange KV segments
One pass completes when every node has seen all parts of the KV
Zero overead for longer sequences: overlap computation and communication
Schema
Problem: slowest ring host determines the pace
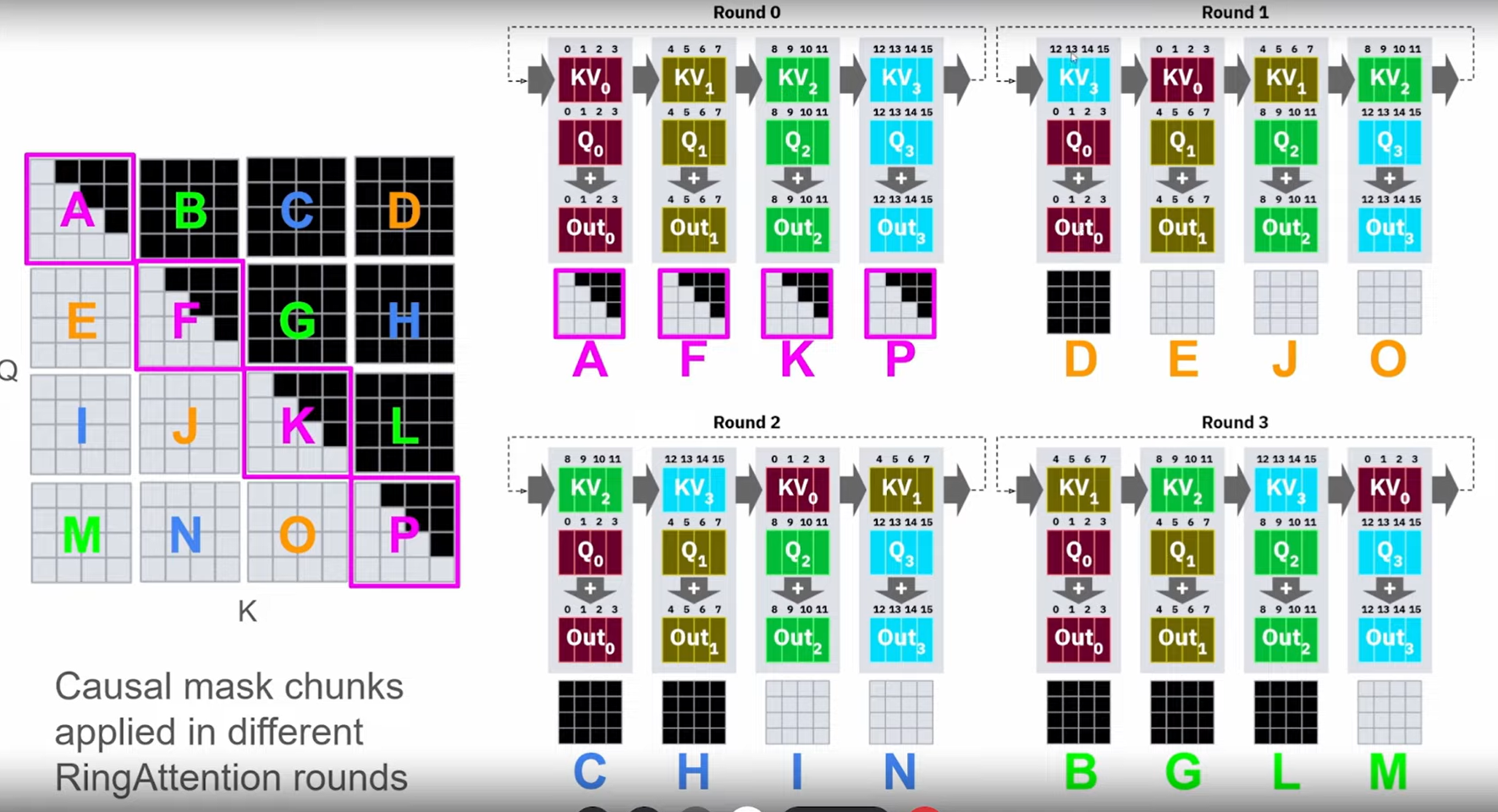
If use causal masking, some devices are idle because of the causal masking preventing computation
i.e. if query indices are larger than the key indices, you skip computation
Striped Attention takes care of this, by reordering the indices inside the blocks to avoid idle GPUs.
Flash-Decoding
During inference with ring attention, one small query matrix Q must wait to pass around all the nodes containing the KV blocks. This is quite inefficient.
Solution: Just send Q to every node (or smaller rings) and reduce at the end