- Hardware-aware architectures
Primer on “Do we need attention?” for sequence modelling
-
FFN acts on each position independently
-
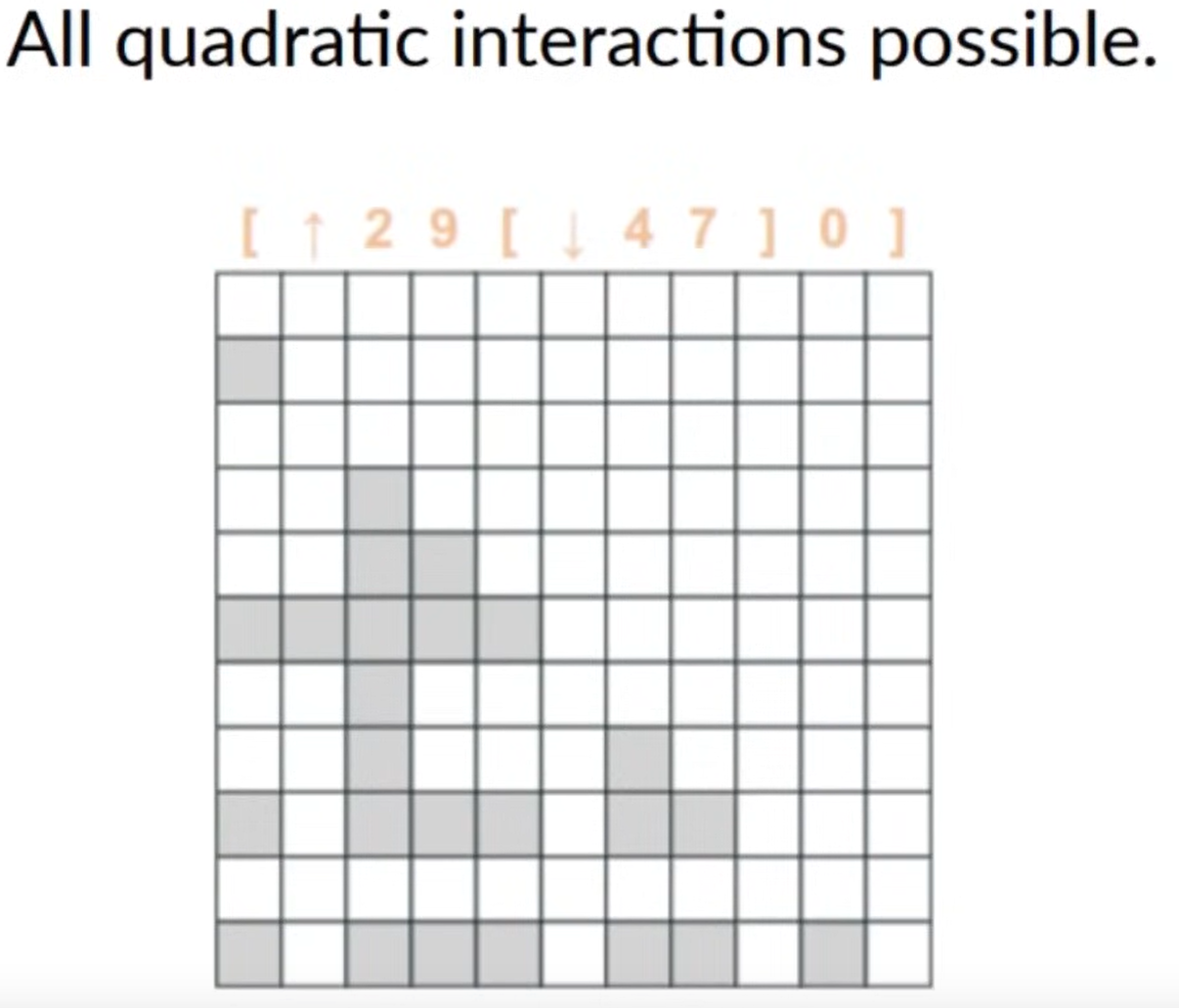
Attention acts on every position in the sequence.
- allows us to dynamically look back at all positions when calculating a sequence prediction
-
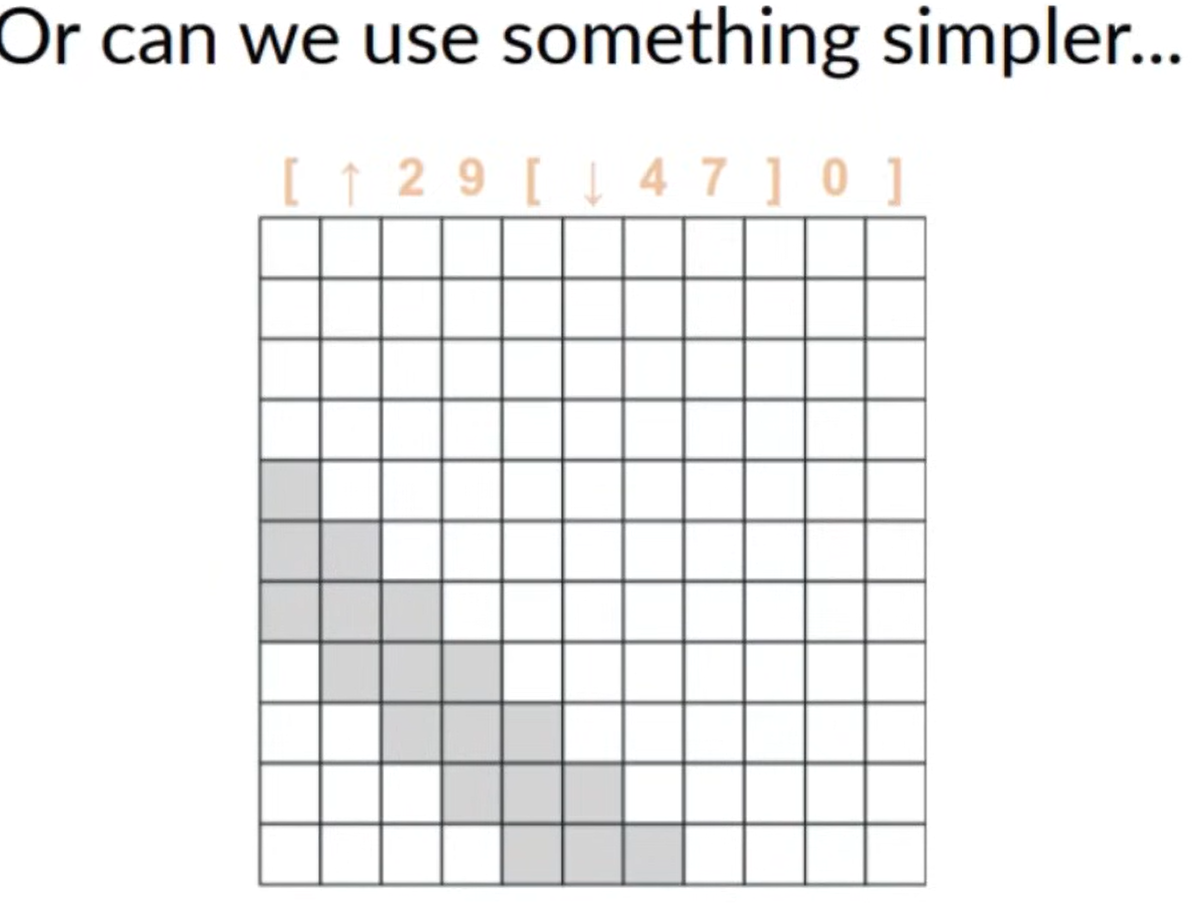
We could use something simpler
-
Attention is still limited by context length
- Training Speed - Cost is quadratic in length
- Generation Speed - Attention requires full lookback
Alternatives to Attention
- Setting: We want to map scalar sequence to scalar sequence
How they’re used
- Similar to a transformer, we just replace the attention in the transformer block by an RNN structure
- The RNN block takes the input sequence and outputs an output sequence, similarly to a self-attention block
- The only difference is that the RNN block doesn’t do a full-sequence lookback to compute each value in the sequence, and instead computes a more structured look-back :)
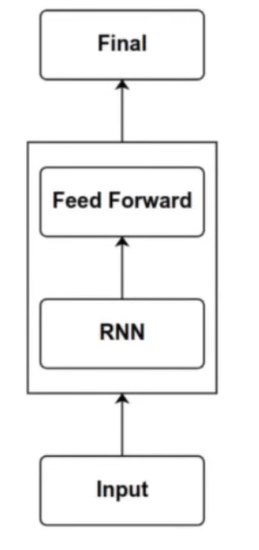
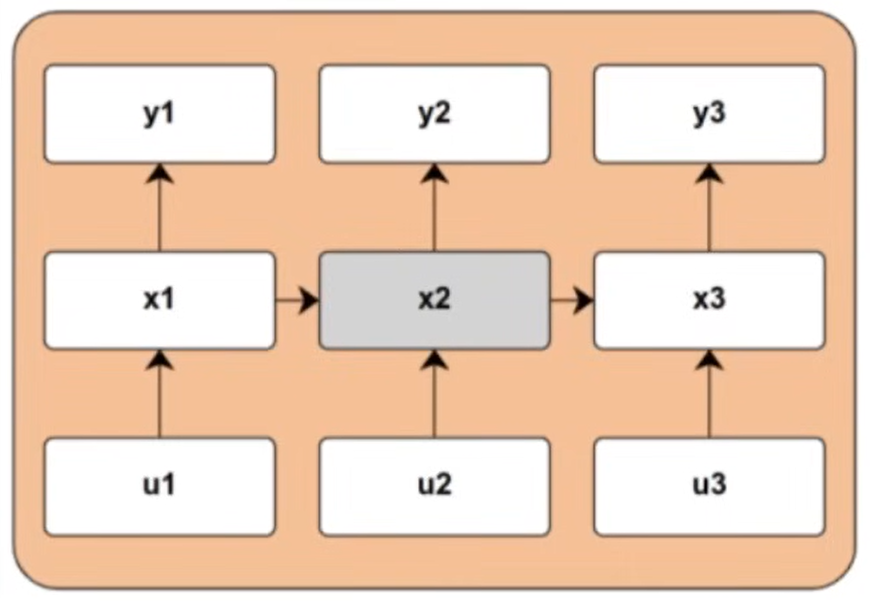
Vanilla RNN
Update rules
Computational graph
Performance
- Training Speed: Slow (Serial bottleneck)
- Generation Speed: Fast (constant-time per step, no need to look back at the entire previous context)
Linear-time variant (LTV) RNNs
Updates rules
-
-
-
Just construct like in Attention, as learnable projections from sequence .
Linear-time invariant (LTI) or Linear RNNs
- Linear RNNS are discretized state space models (SSMs)
Updates rules
Closed form (rolling out the recurrence)
- Let the kernel (it’s a vector)
- Then we get a sliding window convolution form
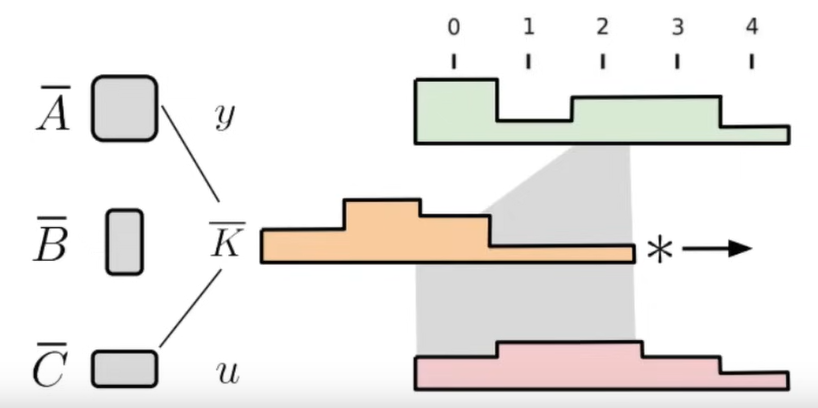
Computation 1: Fourier space
- ONLY WORKS FOR LTI SYSTEMS
- You can compute the convolution in Fourier space
- map and into Fourier Space using FFT,
- compute the product of the individual fourier coefficients
- map back to time space using iFFT,
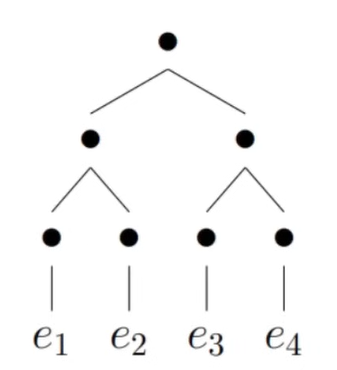
Computation 2: associative scan (S5)
- **It works too for Linear Time Variant RNNs
- (FOR LTI) We have
- (FOR LTV), it’s not the same but we can write
- We can break up the computation into associative terms using what’s called a parallel prefix sum algorithm
- It produces the hidden states instead of directly outputting
- Based on parallel prefix sum algorithm
- with a single processor, this algorithm runs in
- however with around processors, you can get
Performance
- Training Speed: Fast (Parallelizable convolution)
- Generation Speed: Fast (constant-time per step, no need to look back at the entire previous context)
Interactions
-
is not dependent on the input (unlike query, keys in the attention)
-
The choice of the parametrization is critical: stable and informative
- especially the powers of will influence greatly the kernel
-
Example
- LRU paper (periodic):
- where and are learned
- MEGA (damped, exponential moving average)
- very good results on NLP tasks like translation
- Kernel visualisation
- LRU paper (periodic):
-
We study the continuous-time differential equation or State Space Model (SSM) to explore the linear RNN parametrization
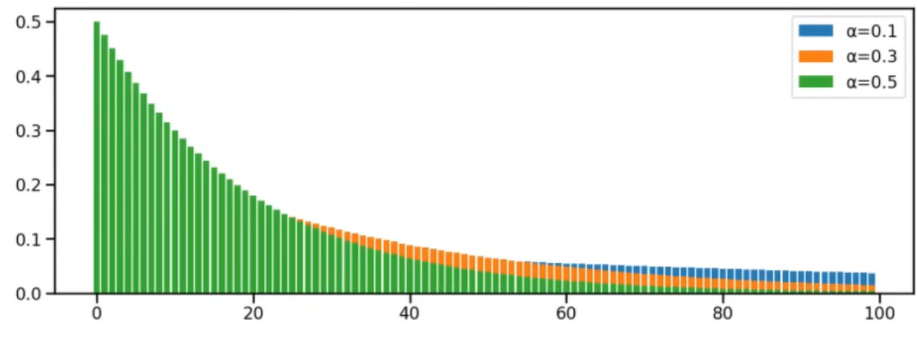
Kernel Visualization
Bidirectional task
- For a bidirectional or non-causal NLP task (i.e. BeRT)
- Visualisation from BiGs of a single layer

- Visualisation from BiGs of a single layer
- Replaces the Attention Matrix
- Single Kernel Per Layer
- All Kernels Visualisation
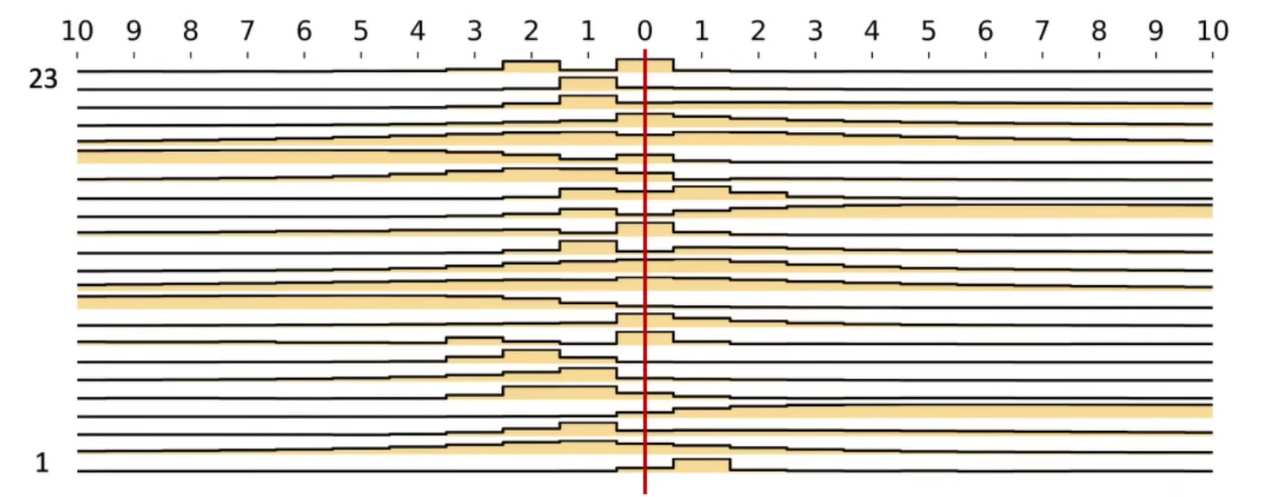
Performance issues
- Linear RNNs really shine in very long context, but don’t have huge savings yet in smaller context
Issues on Accelerators
- Support for complex numbers
- Support for FFT (lower precision, TPU)
- Numerical Stability
- Fast Associative Scans
- Hard to compete with pure MatMul in Attention
