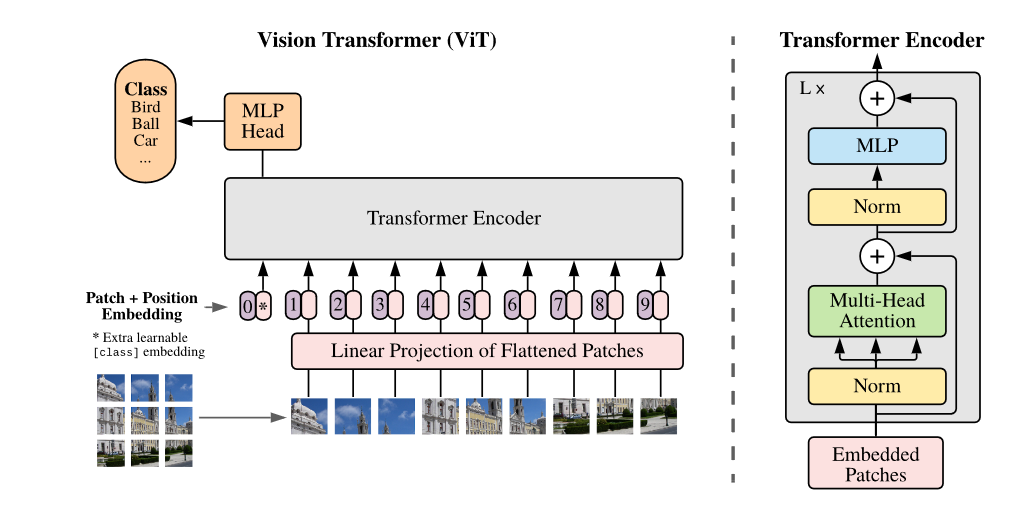
feed the resulting sequence of vectors to a standard Transformer encoder.
In order to perform classification, they use the standard approach of adding an extra learnable “classification token” to the sequence.
Diagram
Patchify + getting token sequence
To do the patchify + linear projection, you can define patch_embedding = nn.Conv2d(in_channels=config.num_channels,out_channels=self.embed_dim,kernel_size=self.patch_size, stride=self.patch_size, bias=False,)
This way, you get a token sequence dependent on resolution.
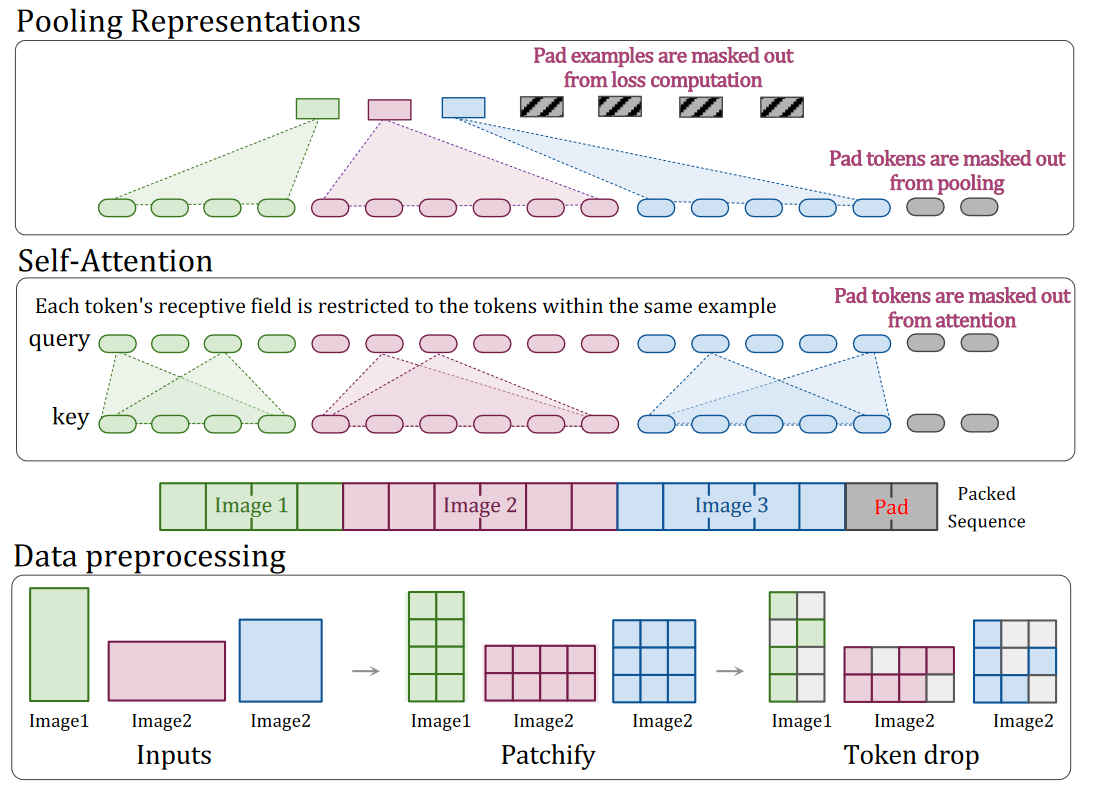
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Inspired by example packing in NLP, where multiple examples are packed into a single sequence to accommodate efficient training on variable length inputs
Multiple patches from different images are packed in a single sequence— termed Patch n’ Pack —which enables variable resolution while preserving the aspect ratio