-
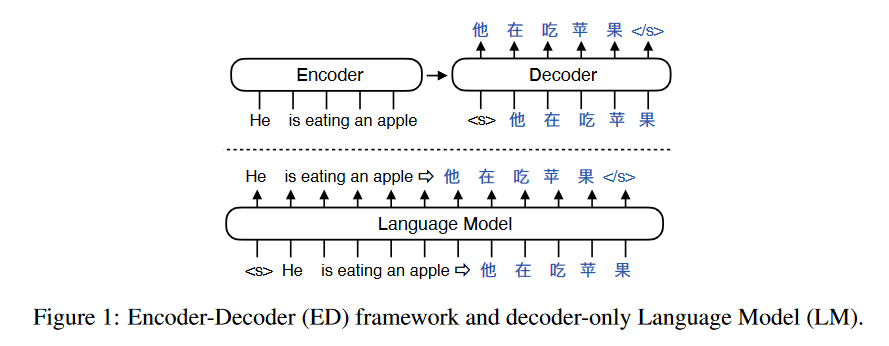
Encoder process the input using non-causal/full self-attention, the resulting embeddings are fed to the decoder part through cross-attention i.e. query=Q(encoder_emb), key, value= K(output_emb), V(output_emb)
-
From “UL2: Unifying Language Learning Paradigms”
- Encoder-Decoder models process input and targets independently with a different set of parameters. This is a form of sparsity where different set of parameters are used for different tokens. Encoder-Decoder models also have a cross attention component that connects input tokens to target tokens. Meanwhile, decoder-only models process inputs and targets by concatenating them. Hence, the representations of inputs and targets are concurrently build layer by layer as the input/targets propagate up the network. Conversely, the decoder in Encoder-decoder models generally only looks at the fully processed encoder input. The distinct property is that Encoder-Decoder models are generally approximately 2x parameters of a decoder-only model when compute-matched.
- From “Decoder-Only or Encoder-Decoder? Interpreting Language Model as a Regularized Encoder-Decode”