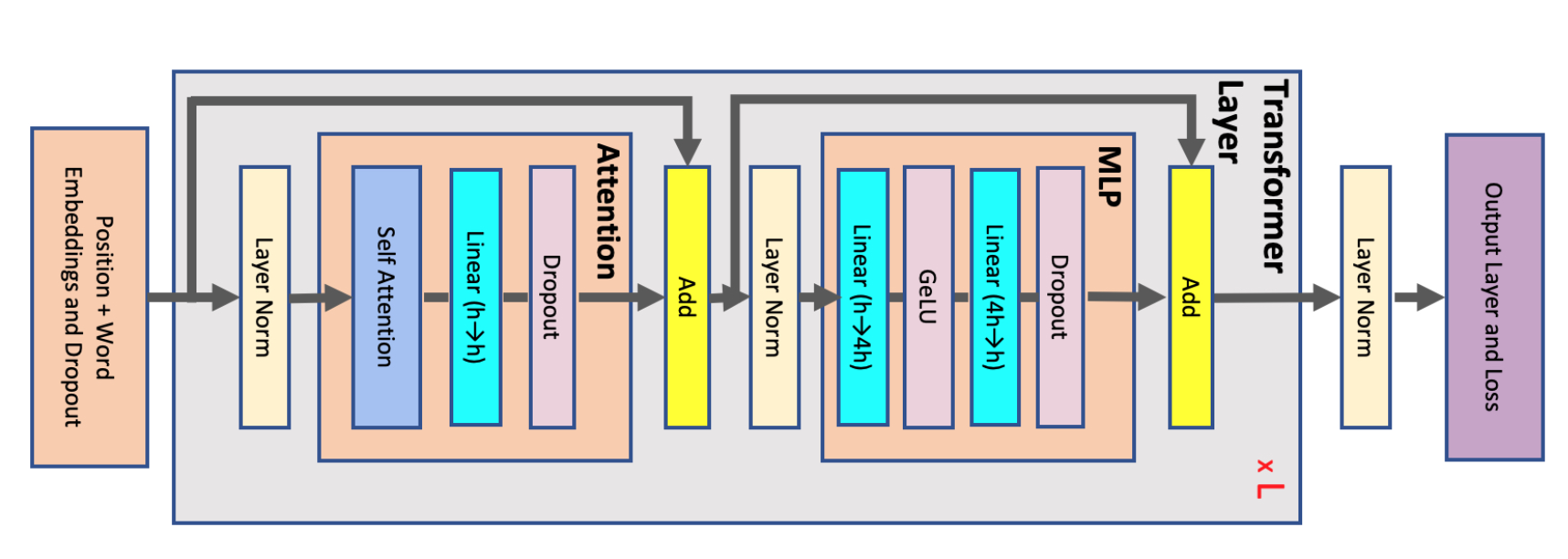
Pre-Layer Norm: By normalizing the input before the sub-layer, the gradients are less likely to explode or vanish as they propagate through the network. This helps maintain a stable gradient flow, which is critical for training deep networks like transformers.
Post-Layer Norm: When layer normalization is applied after the sub-layer, the gradients can still experience instability due to the unnormalized computations within the sub-layer. This can lead to exploding or vanishing gradients, making training harder.
2. Stabilized Training Dynamics:
Pre-Layer Norm: Pre-normalizing helps to ensure that the inputs to each sub-layer have a consistent scale and distribution. This regularity can make the optimization landscape smoother, leading to more stable and efficient training.
Post-Layer Norm: In post-layer normalization, the sub-layer operations can produce outputs with varied scales, which are only normalized at the end. This inconsistency can introduce instability in the training process.