-
heterogeneous: CPU + GPU
CUDA C
-
extends ANSI C with minimal new syntax
-
Terminology: CPU=host, GPU=device
- CUDA C source can be mixture of host & device code
- device code functions: kernels
- grid of threads: many threads are launched to execute a kernel
- don’t be afraid of launching many threads
- e.g. one thread per (output) tensor element
-
CPU & GPU code runs concurrently (overlapped)
Example: Vector addition
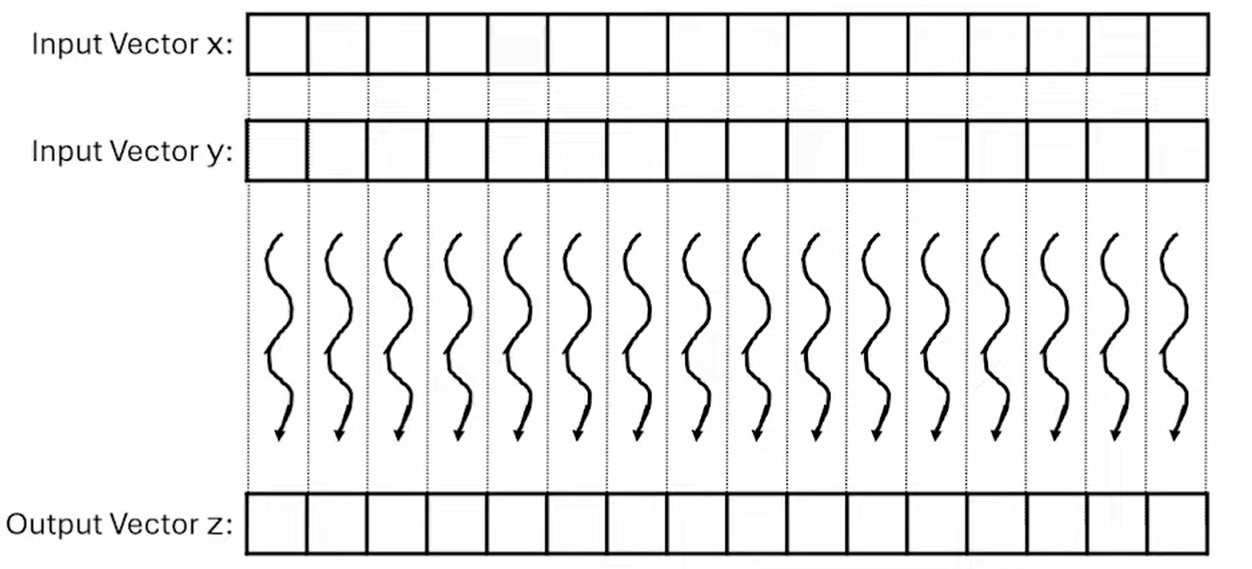
- Naive GPU vector addition:
- Allocate device memory for vectors
- Transfer inputs host → device
- Launch kernel and perform additions
- Copy device → host back
- Free device memory
- Normally, we keep data on the GPU as long as possible to asynchronously schedule many kernel launches.
- For vector addition, we can calculate the array index of the thread:
int i = blockIdx.x * blockDim.x + threadIdx.x;- select the block + assign position within the block
CUDA code
- General strategy: replace loop by grid of threads
- To keep in mind:
- Data sizes might not perfectly divisible by block sizes: always check bounds
- Prevent threads of boundary block to read/write outside allocated memory
// compute vector sum C=A+B
// each thread performs one pairwise addition
__global__
void vecAddKernel(float* A, float *B, float* C, int n){
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n){
C[i] = A[i] + B[i];
}
}