CoreAttention
CausalSelfAttention
QKV proj
qkv_projis aTensorParallelColumnLineard_qk= d_model // num_attention_headsin_features=d_modelout_features= num_attention_heads*d_qk + 2* num_key_value_heads d_qk- support for MQA/GQA Self-Attention (to shrink the kv cache size)
- mqa ⇒ num_key_value_heads=1
- support for MQA/GQA Self-Attention (to shrink the kv cache size)
- to spit out nicely separated over which we can apply attention easily, we must define
contigous_chunks = (num_attention_heads * d_qk, num_key_value_heads * d_qk, num_key_value_heads * d_qk)
OuterProj
o_projis aTensorParallelRowLinear(d_model,d_model)
CoreAttention
- Is checkpointed using decorator
@checkpoint_method(attr_name="checkpoint_attention") - because it sits in between
qkv_proj(ColumnLinear) ando_proj(RowLinear), there’s no need to think about anything distributed - just usual attention (code is still not great to look at because we’re using
flash_attn_varlen_func)
MLP
-
need to pass TP mode (all_reduce or reduce_scatter) and TP process group
-
All complexity is handled by TensorParallel paradigms
-
In Llama, they want to use
GLUActivationfor theup_proj, which is basically activation & gating.def forward(x):gate_states, up_states = torch.split(x, merged_states.shape[-1] // 2, dim=-1)return self.act(gate_states) * up_states
-
Thus you need to define
contiguous_chunks = (intermediate_size, intermediate_size)such that the nn.Linear is sharded correctly. -
gate_up_proj = TensorParallelColumnLinear(hidden_size, 2*intermediate_size, contigous_chunks, pg=tp_pg) -
down_proj = TensorParallelRowLinear(intermediate_size, hidden_size, pg=tp_pg) -
forward(x) = down_proj(GLUActivation(gate_up_proj(x)))
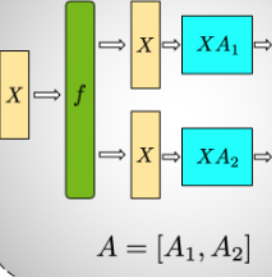
TensorParallelColumnLinear
- Diagram
- Signature
__init__(in_features, out_features, pg, mode, ...)- init under the hood as
nn.Linear(in_features, out_features // tp_pg.size()) - automatic sharding
- init under the hood as
- How we mark the parameters as sharded
- define
split_dim=0for sharding by the column, because a module = nn.Linear(in, out) has its weight matrix represented as , such that
- define
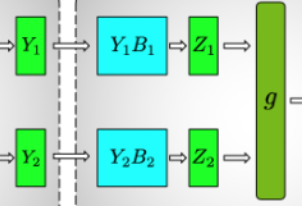
TensorParallelRowLinear
- Diagram
- Signature
__init__(in_features, out_features, pg, mode, ...)- init under the hood as
nn.Linear(in_features // tp_pg.size(), out_features) - automatic sharding
- init under the hood as
- How we mark the parameters as sharded
- define
split_dim=1for sharding by the column, because a module = nn.Linear(in, out) has its weight matrix represented as , such that
- define
- No need to shard the bias term, only rank 0 would have it
- i.e.
bias = dist.get_rank(self.pg) == 0 and biaswhen init the linear layer
- i.e.
TensorParallelEmbedding
- basically a
TensorParallelRowLinearin how it functions - interestingly,
split_dim=0, becausenn.Embeddingstores its embedding matrix in the natural orderrow x column - at
forwardtime,- just need to keep track of which part of the vocab a given process contains, and given the input, mask out the tokens not present in the current vocab
- The
differentiable_reduce_scatter_sumorall_reducewill work well, because each token contains