In practice
-
Blogpost on how to unit scale ops
-
Dirty trick: “Unit-Scale Activation Initialization by Brute Force search”
The idea
-
Technique for model design that operates on the principle of ideal scaling at initialization (unit variance for activations, weights and gradients). This is achieved by considering how each operation in the model affects the variance of different tensors, and introducing fixed scaling factors to counteract changes
-
Empirically, they can train in fp8 and fp16 without loss scaling
-
By ‘training in FP8’ they mean that matmuls are performed in FP8 (inputs are cast down to FP8, with outputs in higher precision)
- weights in E4M3 and gradients in E5M2
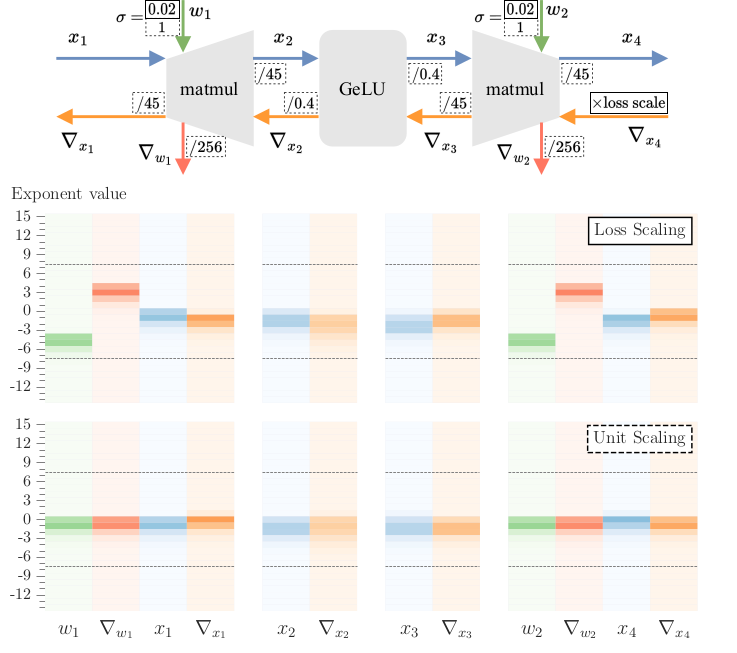
Scaling constraints
- The essence of scale constraints is that for perfect unit scaling, sometimes the ideal scale for the forward pass differs from those in the backward pass. In some special cases (e.g. at the ends of the network) the use of different scales can be valid, but in the general case a single scale must be agreed upon. The solution in the Unit Scaling paper is to use the geometric mean of the forward and backward scales.
- In u-mup, they propose to instead to simply use the forward scale over the backward scale(s) in these cases. They do so for the following reasons:
- For these architectures they find empirically that where there is a disparity in ideal forward and backward scales, it is not large.
- By taking the forward scale, they can ensure strict unit-scale in the forward pass.