We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embedding
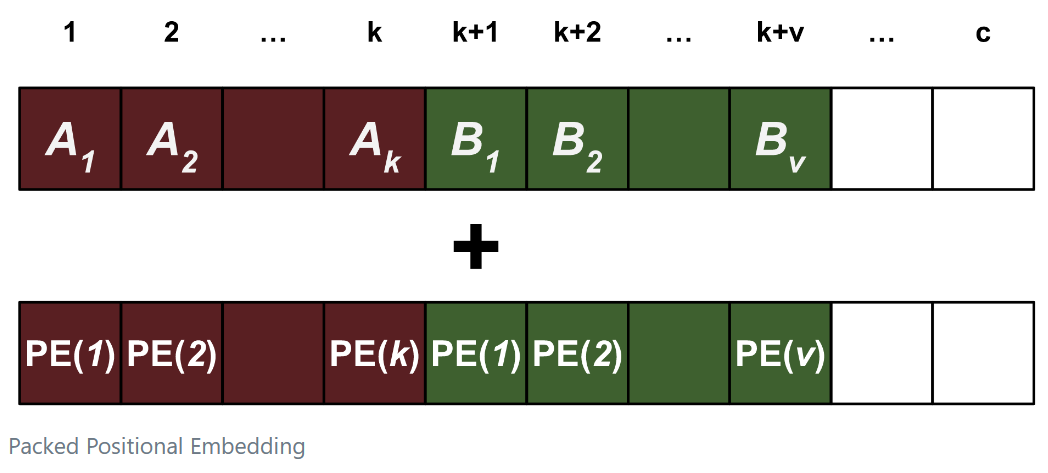
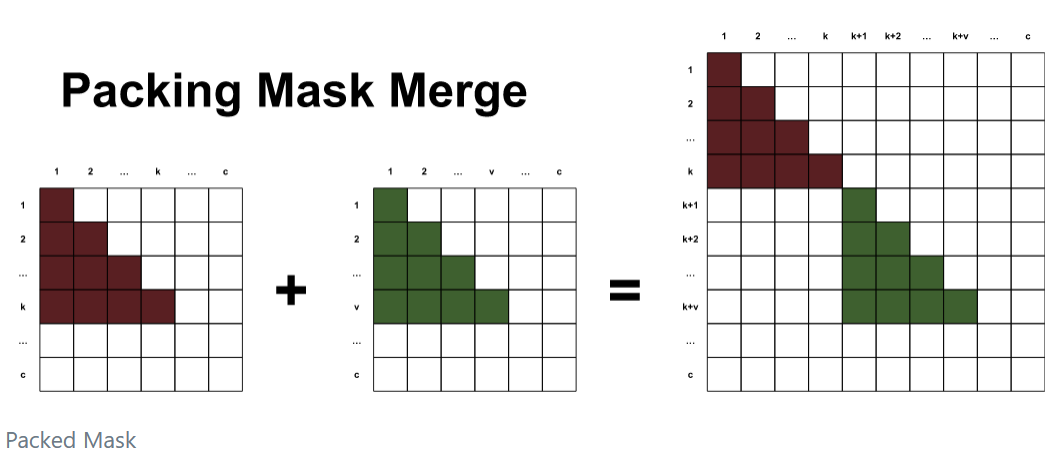
Packing
Source: Exploring the limits of transfer learning with a unified text-to-text transformer.
FLAN-2: We use packing (Raffel et al., 2020) to combine multiple training examples into a single sequence, separating inputs from targets using an end-of-sequence token. Masking is applied to prevent the tokens from attending to others across the packed example boundary.
Things to do
Change in Positional Encoding
Change in Self-Attention Mask
We need to ensure that one sequence cannot attend to another sequence
It’s not a complete free lunch though. We can normally save a single triangular matrix for self attention that is pre-computed, but now we will need an individual mask per sample. Typical flash attention implementations won’t even register a mask but will just perform masking based on the sequence index.