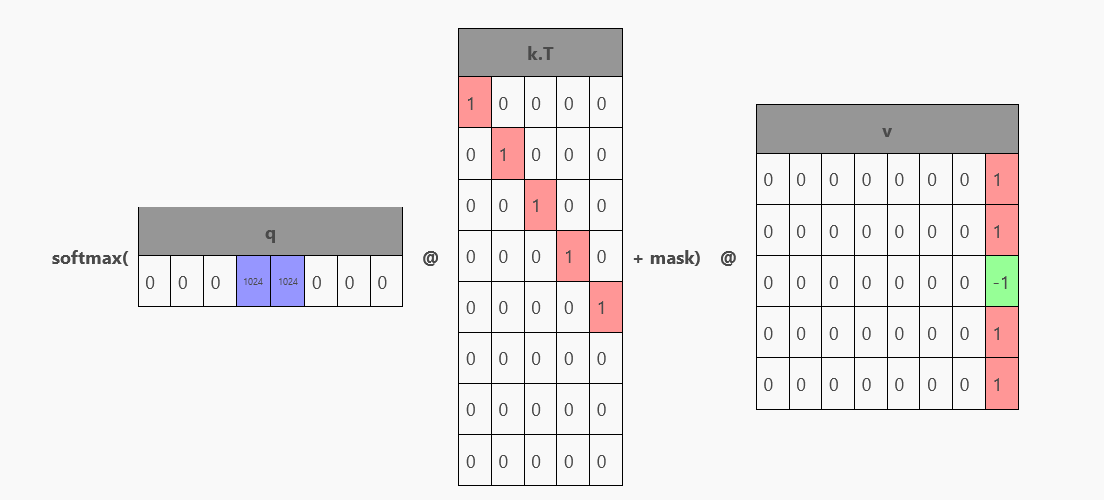
- Related to Self-Attention and vLLM
- Definition: Saving the and matrices rows corresponding to past tokens (for each attention layer) from the last inference step ⇒ in auto-regressive sampling, at each forward pass, we only need to compute the new rows in corresponding to the new token