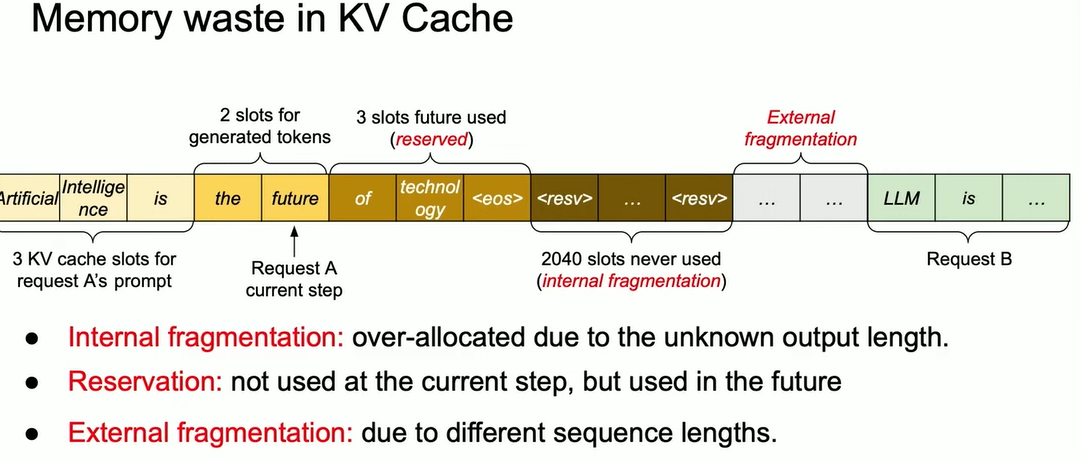
- Related to KV caching
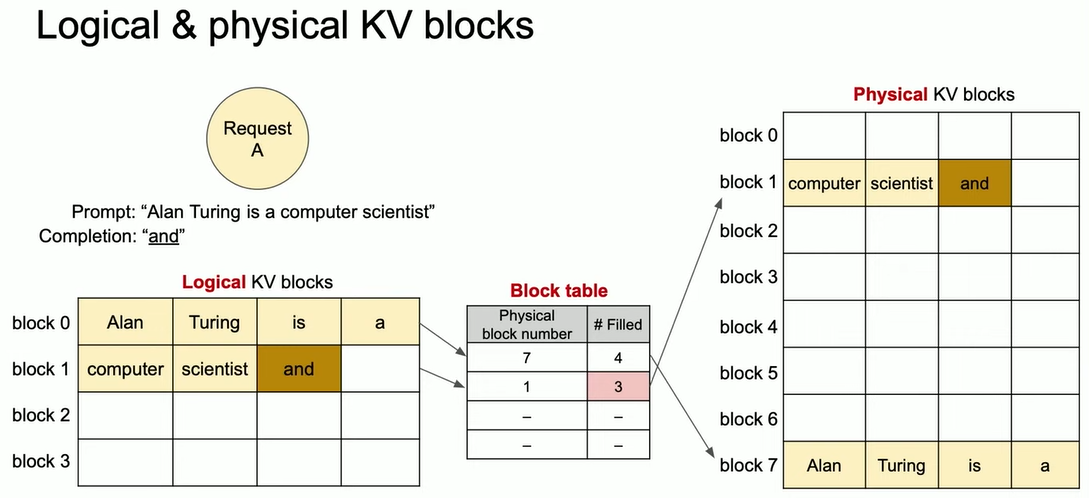
KV block
- A fixed-size contigous chunk memory that can store KV cache from left to right
- Paged Attention thinks that the KV blocks are arranged logically
- A block table actually does the mapping to retrieve the physical KV blocks
- Dynamic block enables KV cache sharing between requests
Paged Attention
-
PagedAttention, an attention algorithm that operates on KV cache stored in non-contiguous paged memory, which is inspired by the virtual memory and paging in OS.
-
Unlike the traditional attention algorithms, PagedAttention allows storing continuous keys and values in non-contiguous memory space. Specifically, PagedAttention partitions the KV cache of each sequence into KV blocks. Each block contains the key and value vectors for a fixed number of tokens,1 which we denote as KV block size (B).
-
Example

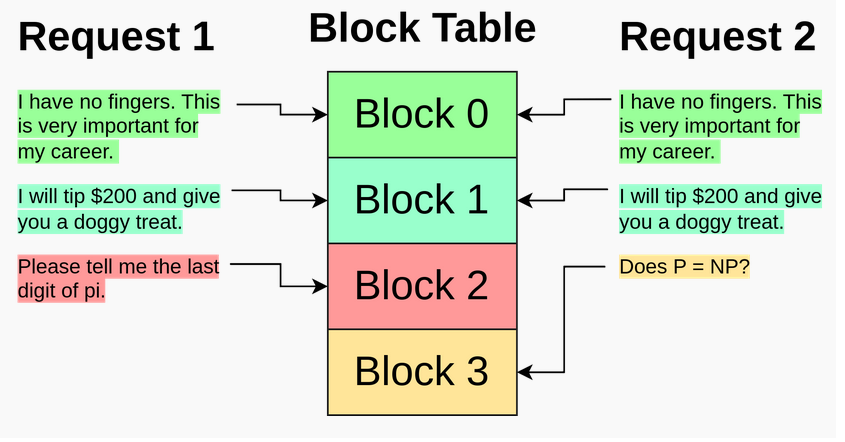
vLLM
- Efficient management of KV cache is crucial for high-throughput LLM serving