- VQ-VAE is a type of variational autoencoder that uses vector quantisation to obtain a discrete latent representation.
- It differs from VAEs in two key ways:
- the encoder network outputs discrete, rather than continuous, codes
- the prior is learnt rather than static
- It differs from VAEs in two key ways:
- In order to learn a discrete latent representation, ideas from vector quantisation (VQ) are incorporated.
- Using the VQ method allows the model to circumvent issues of posterior collapse - where the latents are ignored when they are paired with a powerful autoregressive decoder - typically observed in the VAE framework.
How it works
-
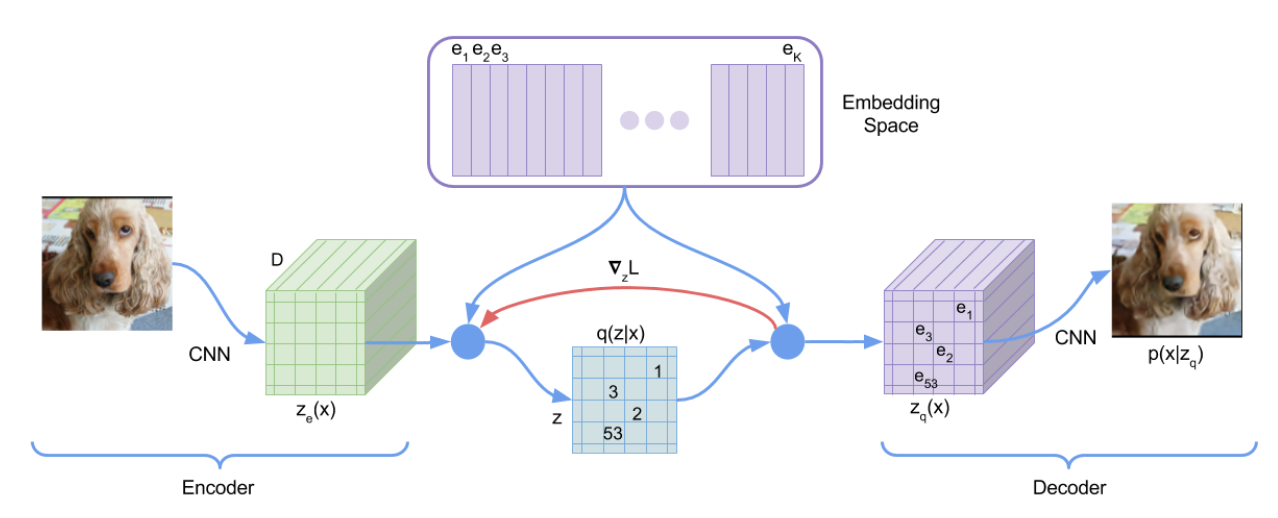
-
Define a latent embedding space ,
- where is the size of the discrete latent space (i.e. K-way categorical, size of vocab)
- is the embedding size.
- Thus, is K-way categorical variable
-
First-step Encoder
- Takes an input , and outputs an embedding
-
Posterior categorical distribution
- Obtained by calculating nearest neighbour in the latent embedding space vocab.
- Outputs either 0 or 1
- It’s deterministic
-
Prior
- If you choose uniform prior over , then you obtain a constant KL divergence, and equal to
- No posterior collapse
-
What is actually fed to the decoder, it’s
- Just the indexing of the embedding table, given the discretized representation of
- where
Learning
- Because of the usage of argmin, and nearest neighbour, there is no real gradient defined between encoder and decoder.
- They approximate the gradient similar to the straight-through estimator and just copy gradients from decoder input to encoder output .
- Why ?
- During forward computation the nearest embedding is passed to the decoder, and during the backwards pass the gradient is passed unaltered to the encoder.
- Since the output representation of the encoder and the input to the decoder share the same dimensional space, the gradients contain useful information for how the encoder has to change its output to lower the reconstruction loss.
Defining the loss
- The loss is defined as
-
stands for the stopgradient operator, defined as identity at forward computation time, and has zero partial derivatives at backward time, thus effectively constraining its operand to be a non-updated constant.
-
the first term is the reconstruction loss
- optimizes decoder and encoder
- due to the straight-through gradient estimation of mapping from to , the embeddings receive no gradients from the reconstruction loss
-
Second term: Vector Quantisation (VQ)
- In order to learn the embedding space, they use one of the simplest dictionary learning algorithm, Vector Quantisation
- The VQ objective uses the error to move the embedding vectors towards the encoder outputs
- In order to learn the embedding space, they use one of the simplest dictionary learning algorithm, Vector Quantisation
-
Third term: commitment loss
- Forcing the volume of the embedding space outputted by to stay bounded
- Since the volume of the embedding space is dimensionless, it can grow arbitrarily if the embeddings do not train as fast as the encoder parameters. To make sure the encoder commits to an embedding and its output does not grow, we add the commitment loss
-