Tokenization
-
Has special tokens
-
<|fim_prefix|>, <|fim_middle|>, and <|fim_suffix|> tokens are used to implement the Fill-in-the-Middle (FIM) technique, where a model predicts the missing parts of a code block. <|fim_pad|> is used for padding during FIM operations.
-
<|repo_name|>, which identifies repository names.
-
<|file_sep|>, used as a file separator to better manage repository-level information.
-
These tokens are essential in helping the model learn from diverse code structures and enable it to handle longer and more complex contexts during both file-level and repo-level pretraining.
Data
Pretraining data
Composition
-
Dataset comprises five key data types: Source Code Data, Text-Code Grounding Data, Synthetic Data, Math Data, and Text Data
-
Source Code: public repositories from GitHub, spanning 92 programming languages
-
Text-Code Grounding Data: code-related documentation, tutorials, blog
-
Synthetic Data: CodeQwen1.5 used to generate large-scale synthetic datasets. Only executable code was retained.
-
Math Data: pre-training corpus from Qwen2.5-Math. mathematical capabilities are useful for good code (algorithms, structured reasoning, …)
-
Text Data: pre-training corpus of the Qwen2.5 model
Mixture
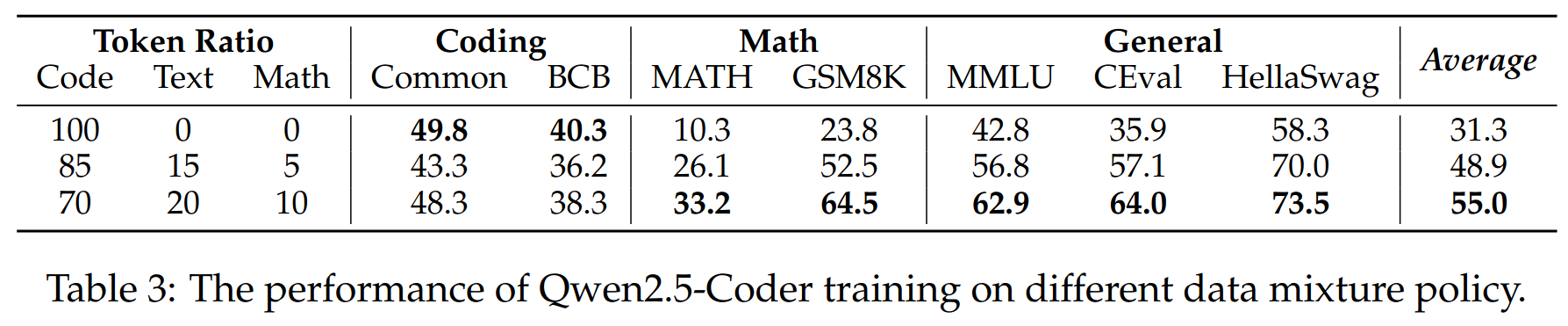
Training policy
-

-
file-level pretraining: 5.2T tokens, individual code files, seq len 8k, next token & FIM
<|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf}<|fim_middle|>{code_mid}<|endoftext|>
-
repo-level pretraining: 300B tokens, entire repos, seq len 32k (rope base freq adjusted to 1M + yarn extrapolation),
- next token + repo-level FIM
<|repo_name|>{repo_name}
<|file_sep|>{file_path1}
{file_content1}
<|file_sep|>{file_path2}
{file_content2}
<|file_sep|>{file_path3}
<|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf}<|fim_middle|>{code_fim}<|endoftext|>
Post-training recipe
Multilingual Programming Code Identification
- finetune CodeBERT to perform language identification to categorize documents in ~100 programming languages.
- randomly discard rare languages samples (prevent overfitting?)
Instruction Synthesis from GitHub
- Use the LLM to generate the instruction from the code snippets within 1024 tokens (e.g. )
- More details on this in Magicoder: Empowering Code Generation with OSS-Instruct
- Use the code LLM to generate an universal code response (i.e. pseudocode)
- Use LLM scorer to filter low-quality ones
- We then have a (instruction, universal code) pair
- Then for any language, you can generate (instruction, universal code, solution) triplet
- Another thing they do for diversity, for multiple languages,
- take code snippet → generate pseudocode → create instruction
- filter
- then have a (instruction, universal code, solution) triplet
Evolving and creating new instructions
-
Main takeaways:
-
They use a multilingual multi-agent collaborative framework to synthesize the multilingual instruction corpora. The agents are language-specific.
-
These agents are initialized with language-specific instruction data derived from the limited existing multilingual instruction corpora. (By initialized, it means that this is the starting seed data from which the agent will evolve)
-
Each agent is responsible for generating instructions for its specific language, it keeps track of its generated instructions using
- Adaptive Memory System: Each agent has a memory system that tracks what it has already generated. This prevents repetition, allowing each agent to keep a fresh perspective and avoid creating the same samples repeatedly.
-
Adaptive Instruction Generation: The framework also includes a mechanism to dynamically generate new instructions based on identified knowledge gaps across languages.
- This can be done by consistently keeping track of a fixed set of concepts/tags and identifying gaps in the overall observed distribution
-
The collaborative part:
- Multiple language-specific agents engage in a structured dialogue to formulate new instructions and solutions.
- Agents share insights and patterns across language boundaries, fostering a more comprehensive understanding of programming concepts
-
-
What to keep track of in your instruction dataset
-
general programming concepts (patterns, algorithms, …)
-
language-specific concepts (python decorators, scala pattern matching, …)
-
Keeping track of such tags allows to have a structured view over your corpus
-
How to score code instruction data (checklist-based)
- Question&Answer Consistency: Whether Q&A are consistent and correct for fine-tuning.
- Question&Answer Relevance: Whether Q&A are related to the computer field
- Question&Answer Difficulty: Whether Q&A are sufficiently challenging.
- Code Exist: Whether the code is provied in question or answer.
- Code Correctness: Evaluate whether the provided code is free from syntax errors and logical flaws.
- Consider factors like proper variable naming, code indentation, and adherence to best practices.
- Code Clarity: Assess how clear and understandable the code is. Evaluate if it uses meaningful variable names, proper comments, and follows a consistent coding style.
- Code Comments: Evaluate the presence of comments and their usefulness in explaining the code’s functionality.
- Easy to Learn: determine its educational value for a student whose goal is to learn basic coding concepts
- After gaining all scores , we can get the final score with , where are a series of pre-defined weights
Mutlilingual sandbox for code verification
-
Only the self-contained (e.g. algorithm problems) code snippet will be fed into the multilingual sandbox.
-
What it does:
- Abstract Syntax Tree parsing & static analysis module*
- can filter out code with parsing errors (unclosed brackets, missing keywords, …)
- Unit test generator
- Analyzes sample code to identify key functionalities and edge cases
- Automatically generates unit tests based on the expected behavior
- Code Execution Engine
- isolated environment for executing code snippets securely (handles resource allocation and timeout mechanisms)
- parallel execution of test cases
- Result Analyzer
- Compares the output of code snippets against expected results from unit test
- Generate detailed reports on test case successes and failures
- Provides suggestions for improvements based on failed test cases
- Abstract Syntax Tree parsing & static analysis module*
Final mixture
- Coarse-to-fine Fine-tuning
- synthesized tens of millions of low-quality but diverse instruction samples to fine-tune the base model.
- In the second stage, millions of high-quality instruction samples to improve the performance of the instruction model with rejection sampling and supervised fine-tuning.
- For the same query, they generate multiple candidates and then score the best one for supervised fine-tuning
- Mixed tuning
- They use combination of FIM (o keep the long context capability of the base mode)+ normal SFT
- For FIM, they use the Abstract Syntax Tree to parse the code snippets and extract the basic logic blocks as the middle code to infill (when using FIM).